publications
I attempt to keep this list up to date. Also check my Google Scholar profile.
2025
Conference Publications
-
Learning from 10 Demos: Generalisable and Sample-Efficient Policy Learning with Oriented Affordance Frames In Conference on Robot Learning (CoRL), 2025.
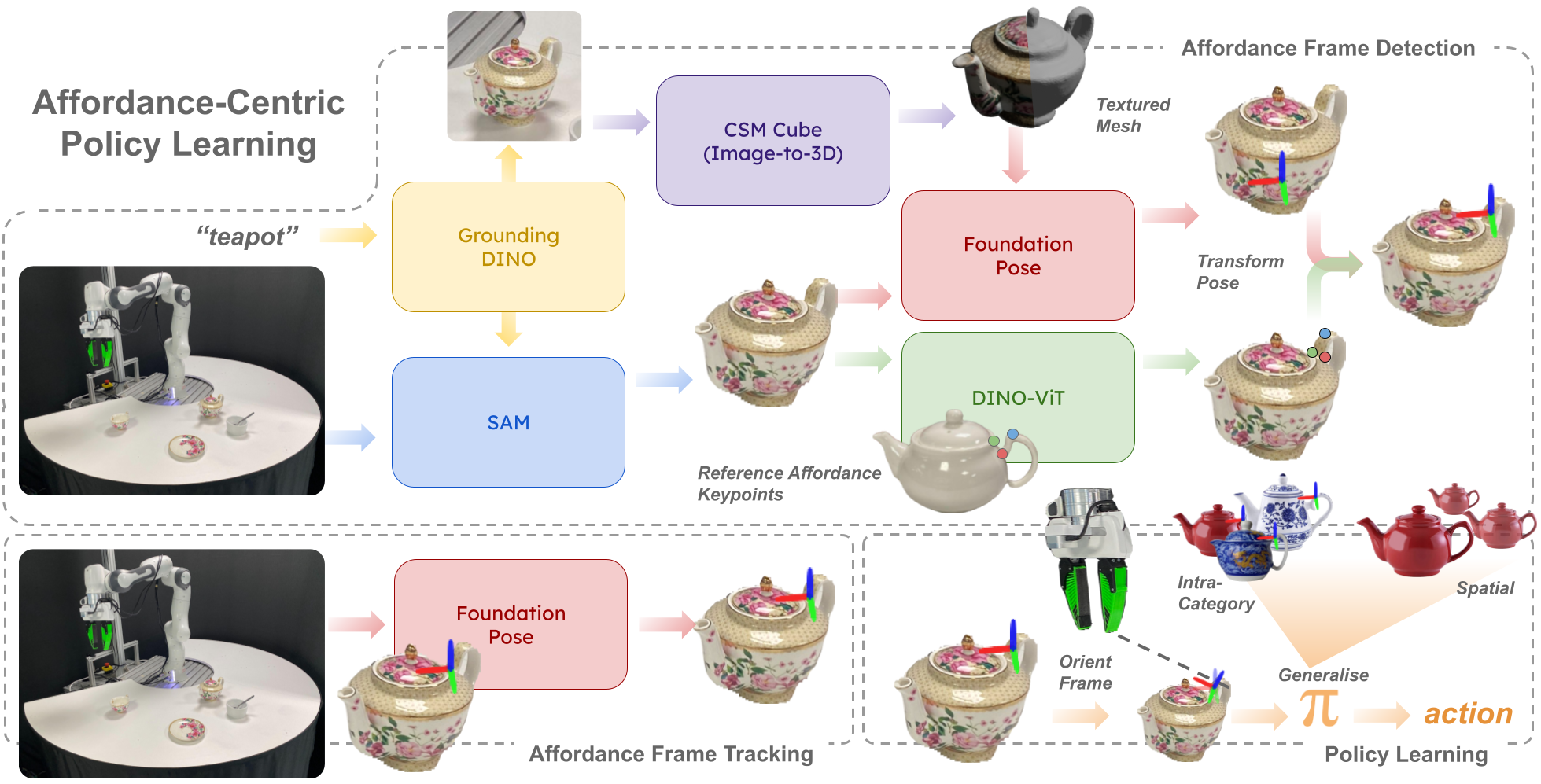 We introduce oriented affordance frames, a structured representation for state and action spaces that improves spatial and intra-category generalisation and enables policies to be learned efficiently from only 10 demonstrations. More importantly, we show how this abstraction allows for compositional generalisation of independently trained sub-policies to solve long-horizon, multi-object tasks. To seamlessly transition between sub-policies, we introduce the notion of self-progress prediction, which we directly derive from the duration of the training demonstrations. We validate our method across three real-world tasks, each requiring multi-step, multi-object interactions. Despite the small dataset, our policies generalise robustly to unseen object appearances, geometries, and spatial arrangements, achieving high success rates without reliance on exhaustive training data.
[arXiv]
[website]
We introduce oriented affordance frames, a structured representation for state and action spaces that improves spatial and intra-category generalisation and enables policies to be learned efficiently from only 10 demonstrations. More importantly, we show how this abstraction allows for compositional generalisation of independently trained sub-policies to solve long-horizon, multi-object tasks. To seamlessly transition between sub-policies, we introduce the notion of self-progress prediction, which we directly derive from the duration of the training demonstrations. We validate our method across three real-world tasks, each requiring multi-step, multi-object interactions. Despite the small dataset, our policies generalise robustly to unseen object appearances, geometries, and spatial arrangements, achieving high success rates without reliance on exhaustive training data.
[arXiv]
[website]
-
IMLE Policy: Fast and Sample Efficient Visuomotor Policy Learning via Implicit Maximum Likelihood Estimation In Robotics: Science and Systems (RSS), 2025.
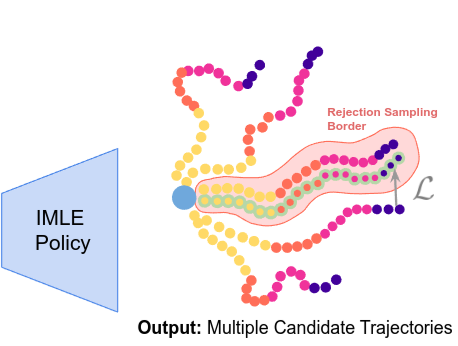 We introduce IMLE Policy, a novel behaviour cloning approach based on Implicit Maximum Likelihood Estimation (IMLE). IMLE Policy excels in low-data regimes, effectively learning from minimal demonstrations and requiring 38% less data on average to match the performance of baseline methods in learning complex multi-modal behaviours. Its simple generator-based architecture enables single-step action generation, improving inference speed by 97.3% compared to Diffusion Policy, while outperforming single-step Flow Matching.
[arXiv]
[website]
We introduce IMLE Policy, a novel behaviour cloning approach based on Implicit Maximum Likelihood Estimation (IMLE). IMLE Policy excels in low-data regimes, effectively learning from minimal demonstrations and requiring 38% less data on average to match the performance of baseline methods in learning complex multi-modal behaviours. Its simple generator-based architecture enables single-step action generation, improving inference speed by 97.3% compared to Diffusion Policy, while outperforming single-step Flow Matching.
[arXiv]
[website]
-
RMMI: Enhanced Obstacle Avoidance for Reactive Mobile Manipulation using an Implicit Neural Map In International Conference on Intelligent Robots and Systems (IROS), 2025.
 We introduce a novel reactive control framework for mobile manipulators operating in complex, static environments. Our approach leverages a neural Signed Distance Field (SDF) to model intricate environment details and incorporates this representation as inequality constraints within a Quadratic Program (QP) to coordinate robot joint and base motion. A key contribution is the introduction of an active collision avoidance cost term that maximises the total robot distance to obstacles during the motion. We first evaluate our approach in a simulated reaching task, outperforming previous methods that rely on representing both the robot and the scene as a set of primitive geometries. Compared with the baseline, we improved the task success rate by 25% in total, which includes increases of 10% by using the active collision cost. We also demonstrate our approach on a real-world platform, showing its effectiveness in reaching target poses in cluttered and confined spaces using environment models built directly from sensor data
[arXiv]
[website]
We introduce a novel reactive control framework for mobile manipulators operating in complex, static environments. Our approach leverages a neural Signed Distance Field (SDF) to model intricate environment details and incorporates this representation as inequality constraints within a Quadratic Program (QP) to coordinate robot joint and base motion. A key contribution is the introduction of an active collision avoidance cost term that maximises the total robot distance to obstacles during the motion. We first evaluate our approach in a simulated reaching task, outperforming previous methods that rely on representing both the robot and the scene as a set of primitive geometries. Compared with the baseline, we improved the task success rate by 25% in total, which includes increases of 10% by using the active collision cost. We also demonstrate our approach on a real-world platform, showing its effectiveness in reaching target poses in cluttered and confined spaces using environment models built directly from sensor data
[arXiv]
[website]
-
Multi-View Pose-Agnostic Change Localization with Zero Labels In Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
 We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn additional change channels in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7 and 1.6 improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
[arXiv]
We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn additional change channels in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7 and 1.6 improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
[arXiv]
arXiv Preprints
-
Real-is-Sim: Bridging the Sim-to-Real Gap with a Dynamic Digital Twin for Real-World Robot Policy Evaluation arXiv preprint arXiv:2504.03597, 2025.
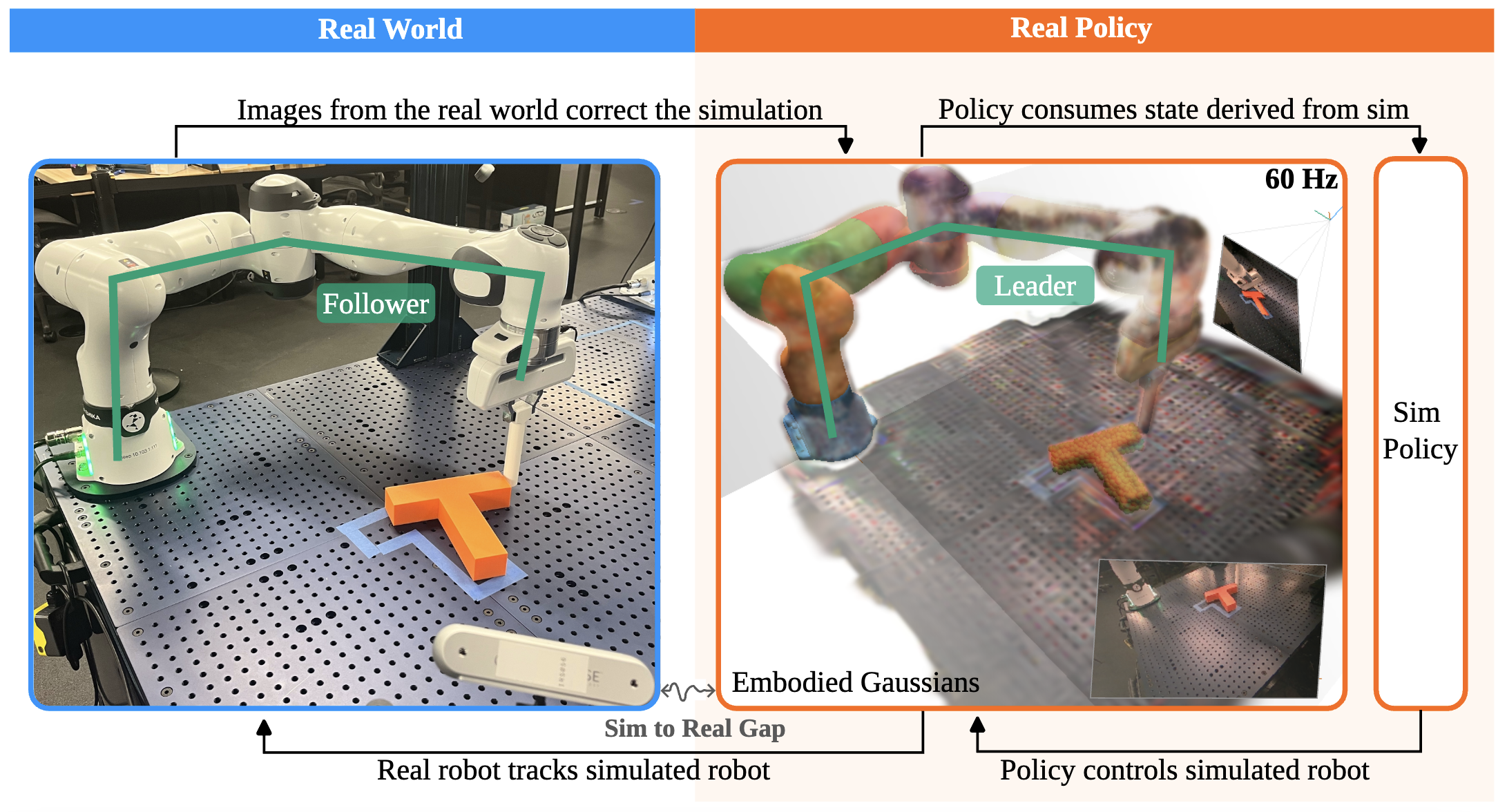 We introduce real-is-sim, a new approach to integrating simulation into behavior cloning pipelines. In contrast to real-only methods, which lack the ability to safely test policies before deployment, and sim-to-real methods, which require complex adaptation to cross the sim-to-real gap, our framework allows policies to seamlessly switch between running on real hardware and running in parallelized virtual environments. At the center of real-is-sim is a dynamic digital twin, powered by the Embodied Gaussian simulator, that synchronizes with the real world at 60Hz. This twin acts as a mediator between the behavior cloning policy and the real robot. Policies are trained using representations derived from simulator states and always act on the simulated robot, never the real one. During deployment, the real robot simply follows the simulated robot’s joint states, and the simulation is continuously corrected with real world measurements. This setup, where the simulator drives all policy execution and maintains real-time synchronization with the physical world, shifts the responsibility of crossing the sim-to-real gap to the digital twin’s synchronization mechanisms, instead of the policy itself.
[arXiv]
[website]
We introduce real-is-sim, a new approach to integrating simulation into behavior cloning pipelines. In contrast to real-only methods, which lack the ability to safely test policies before deployment, and sim-to-real methods, which require complex adaptation to cross the sim-to-real gap, our framework allows policies to seamlessly switch between running on real hardware and running in parallelized virtual environments. At the center of real-is-sim is a dynamic digital twin, powered by the Embodied Gaussian simulator, that synchronizes with the real world at 60Hz. This twin acts as a mediator between the behavior cloning policy and the real robot. Policies are trained using representations derived from simulator states and always act on the simulated robot, never the real one. During deployment, the real robot simply follows the simulated robot’s joint states, and the simulation is continuously corrected with real world measurements. This setup, where the simulator drives all policy execution and maintains real-time synchronization with the physical world, shifts the responsibility of crossing the sim-to-real gap to the digital twin’s synchronization mechanisms, instead of the policy itself.
[arXiv]
[website]
2024
Journal Articles
-
Inherently privacy-preserving vision for trustworthy autonomous systems: Needs and solutions Journal of Responsible Technology, 2024.
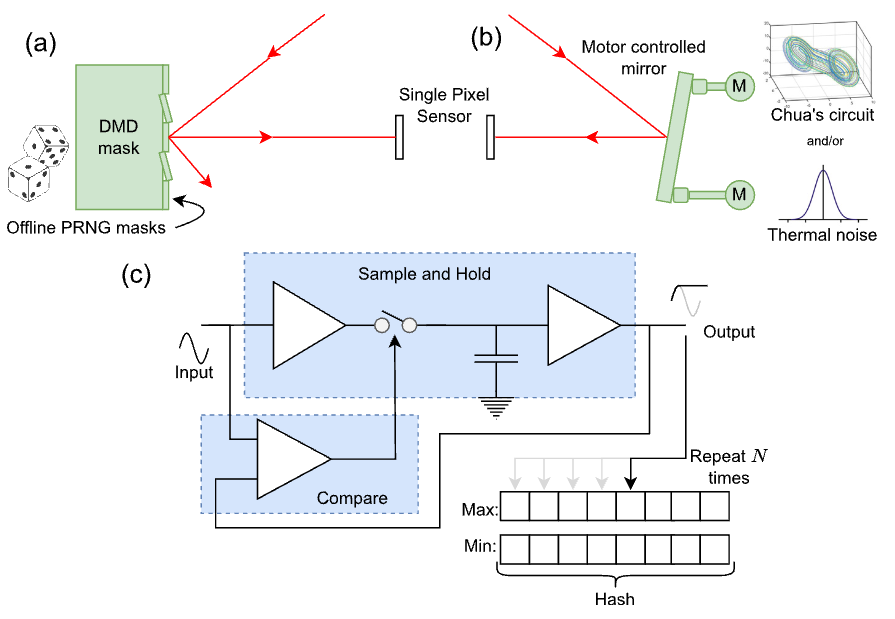 This paper is a call to action to consider privacy in robotic vision. We propose a specific form of inherent privacy preservation in which no images are captured or could be reconstructed by an attacker, even with full remote access. We present a set of principles by which such systems could be designed, employing data-destroying operations and obfuscation in the optical and analogue domains. These cameras never see a full scene. Our localisation case study demonstrates in simulation four implementations that all fulfil this task. The design space of such systems is vast despite the constraints of optical-analogue processing. We hope to inspire future works that expand the range of applications open to sighted robotic systems.
[website]
This paper is a call to action to consider privacy in robotic vision. We propose a specific form of inherent privacy preservation in which no images are captured or could be reconstructed by an attacker, even with full remote access. We present a set of principles by which such systems could be designed, employing data-destroying operations and obfuscation in the optical and analogue domains. These cameras never see a full scene. Our localisation case study demonstrates in simulation four implementations that all fulfil this task. The design space of such systems is vast despite the constraints of optical-analogue processing. We hope to inspire future works that expand the range of applications open to sighted robotic systems.
[website]
Conference Publications
-
Physically Embodied Gaussian Splatting: A Realtime Correctable World Model for Robotics In Conference on Robot Learning (CoRL), 2024. Oral Presentation
 We propose a novel dual "Gaussian-Particle" representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates "visual forces" that correct the particle positions while respecting known physical constraints. By integrating predictive physical modeling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality.
[arXiv]
[website]
We propose a novel dual "Gaussian-Particle" representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates "visual forces" that correct the particle positions while respecting known physical constraints. By integrating predictive physical modeling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality.
[arXiv]
[website]
-
Open-Set Recognition in the Age of Vision-Language Models In European Conference on Computer Vision (ECCV), 2024.
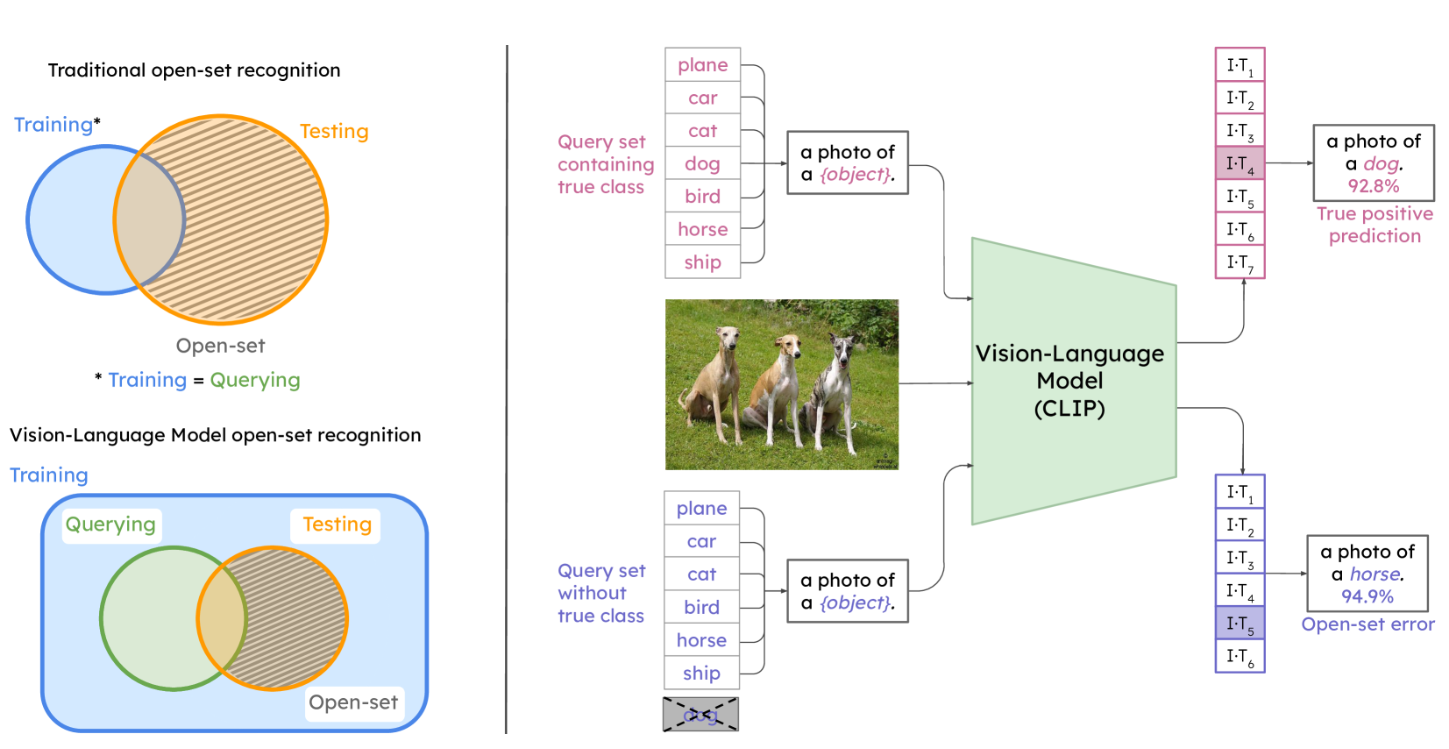 Are vision-language models (VLMs) open-set models because they are trained on internet-scale datasets? We answer this question with a clear no – VLMs introduce closed-set assumptions via their finite query set, making them vulnerable to open-set conditions. We systematically evaluate VLMs for open-set recognition and find they frequently misclassify objects not contained in their query set, leading to alarmingly low precision when tuned for high recall and vice versa. We show that naively increasing the size of the query set to contain more and more classes does not mitigate this problem, but instead causes diminishing task performance and open-set performance. We establish a revised definition of the open-set problem for the age of VLMs, define a new benchmark and evaluation protocol to facilitate standardised evaluation and research in this important area, and evaluate promising baseline approaches based on predictive uncertainty and dedicated negative embeddings on a range of VLM classifiers and object detectors.
[arXiv]
[Code]
Are vision-language models (VLMs) open-set models because they are trained on internet-scale datasets? We answer this question with a clear no – VLMs introduce closed-set assumptions via their finite query set, making them vulnerable to open-set conditions. We systematically evaluate VLMs for open-set recognition and find they frequently misclassify objects not contained in their query set, leading to alarmingly low precision when tuned for high recall and vice versa. We show that naively increasing the size of the query set to contain more and more classes does not mitigate this problem, but instead causes diminishing task performance and open-set performance. We establish a revised definition of the open-set problem for the age of VLMs, define a new benchmark and evaluation protocol to facilitate standardised evaluation and research in this important area, and evaluate promising baseline approaches based on predictive uncertainty and dedicated negative embeddings on a range of VLM classifiers and object detectors.
[arXiv]
[Code]
-
Open X-Embodiment: Robotic Learning Datasets and RT-X Models In IEEE Conference on Robotics and Automation (ICRA), 2024. ICRA Best Conference Paper. ICRA Best Paper Award in Robot Manipulation.
 Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms.
[arXiv]
[website]
Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms.
[arXiv]
[website]
-
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation In IEEE Conference on Robotics and Automation (ICRA), 2024. Oral Presentation at ICRA, Oral Presentation at CoRL Workshop
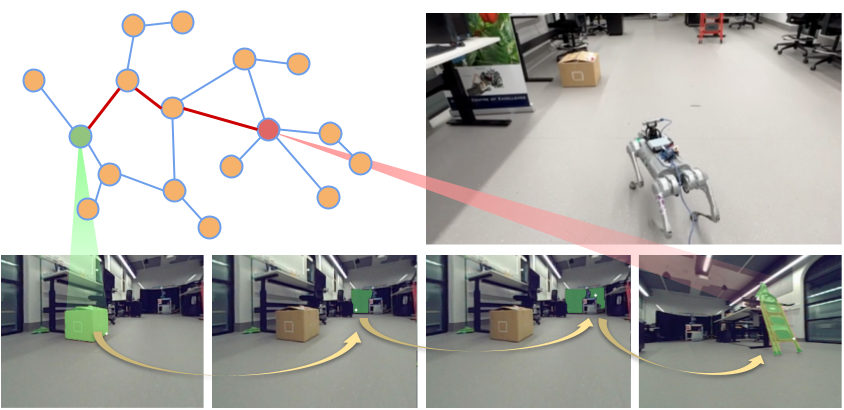 We propose a novel topological representation of an environment based on image segments, which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph but with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a continuous sense of a ‘place’, defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval.
[website]
We propose a novel topological representation of an environment based on image segments, which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph but with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a continuous sense of a ‘place’, defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval.
[website]
-
ParticleNeRF: Particle Based Encoding for Online Neural Radiance Fields in Dynamic Scenes In IEEE Winter Conference on Applications of Computer Vision (WACV), 2024. Best Paper Honourable Mention & Oral Presentation
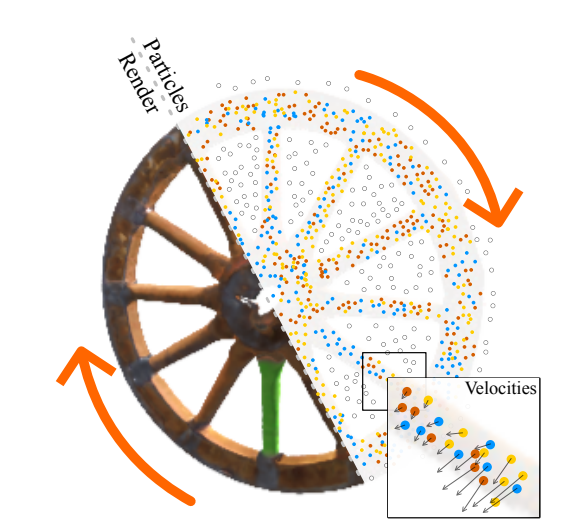 While existing Neural Radiance Fields (NeRFs) for dynamic scenes are offline methods with an emphasis on visual fidelity, our paper addresses the online use case that prioritises real-time adaptability. We present ParticleNeRF, a new approach that dynamically adapts to changes in the scene geometry by learning an up-to-date representation online, every 200ms. ParticleNeRF achieves this using a novel particle-based parametric encoding. We couple features to particles in space and backpropagate the photometric reconstruction loss into the particles’ position gradients, which are then interpreted as velocity vectors. Governed by a lightweight physics system to handle collisions, this lets the features move freely with the changing scene geometry.
[arXiv]
[website]
While existing Neural Radiance Fields (NeRFs) for dynamic scenes are offline methods with an emphasis on visual fidelity, our paper addresses the online use case that prioritises real-time adaptability. We present ParticleNeRF, a new approach that dynamically adapts to changes in the scene geometry by learning an up-to-date representation online, every 200ms. ParticleNeRF achieves this using a novel particle-based parametric encoding. We couple features to particles in space and backpropagate the photometric reconstruction loss into the particles’ position gradients, which are then interpreted as velocity vectors. Governed by a lightweight physics system to handle collisions, this lets the features move freely with the changing scene geometry.
[arXiv]
[website]
Workshop Publications
-
Affordance-Centric Policy Learning: Sample Efficient and Generalisable Robot Policy Learning using Affordance-Centric Task Frames In Workshop on Learning Robotic Assembly of Industrial and Everyday Objects, Conference on Robot Learning (CoRL), 2024.
In this paper, we propose an affordance-centric policy-learning approach that centres and appropriately orients a task frame on these affordance regions allowing us to achieve both intra-category invariance – where policies can generalise across different instances within the same object category – and spatial invariance — which enables consistent performance regardless of object placement in the environment. We propose a method to leverage existing generalist large vision models to extract and track these affordance frames, and demonstrate that our approach can learn manipulation tasks using behaviour cloning from as little as 10 demonstrations, with equivalent generalisation to an image-based policy trained on 305 demonstrations.
[arXiv]
[website]
-
Multi-Modal 3D Scene Graph Updater for Shared and Dynamic Environments In Workshop on Lifelong Learning for Home Robots, Conference on Robot Learning (CoRL), 2024.
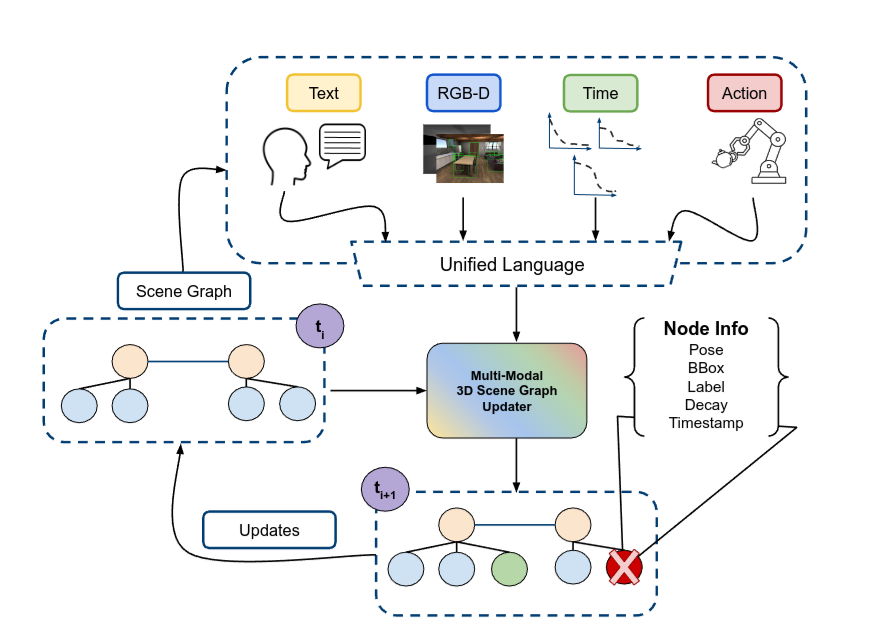 The advent of generalist Large Language Models (LLMs) and Large Vision Models (VLMs) have streamlined the construction of semantically enriched maps that can enable robots to ground high-level reasoning and planning into their representations. One of the most widely used semantic map formats is the 3D Scene Graph, which captures both metric (low-level) and semantic (high-level) information. However, these maps often assume a static world, while real environments, like homes and offices, are dynamic. Even small changes in these spaces can significantly impact task performance. To integrate robots into dynamic environments, they must detect changes and update the scene graph in real-time. This update process is inherently multimodal, requiring input from various sources, such as human agents, the robot’s own perception system, time, and its actions. This work proposes a framework that leverages these multimodal inputs to maintain the consistency of scene graphs during real-time operation, presenting promising initial results and outlining a roadmap for future research.
[arXiv]
The advent of generalist Large Language Models (LLMs) and Large Vision Models (VLMs) have streamlined the construction of semantically enriched maps that can enable robots to ground high-level reasoning and planning into their representations. One of the most widely used semantic map formats is the 3D Scene Graph, which captures both metric (low-level) and semantic (high-level) information. However, these maps often assume a static world, while real environments, like homes and offices, are dynamic. Even small changes in these spaces can significantly impact task performance. To integrate robots into dynamic environments, they must detect changes and update the scene graph in real-time. This update process is inherently multimodal, requiring input from various sources, such as human agents, the robot’s own perception system, time, and its actions. This work proposes a framework that leverages these multimodal inputs to maintain the consistency of scene graphs during real-time operation, presenting promising initial results and outlining a roadmap for future research.
[arXiv]
-
Human-in-the-Loop Segmentation of Multi-species Coral Imagery In CVPR workshop on Learning with Limited Labelled Data for Image and Video Understanding, 2024.
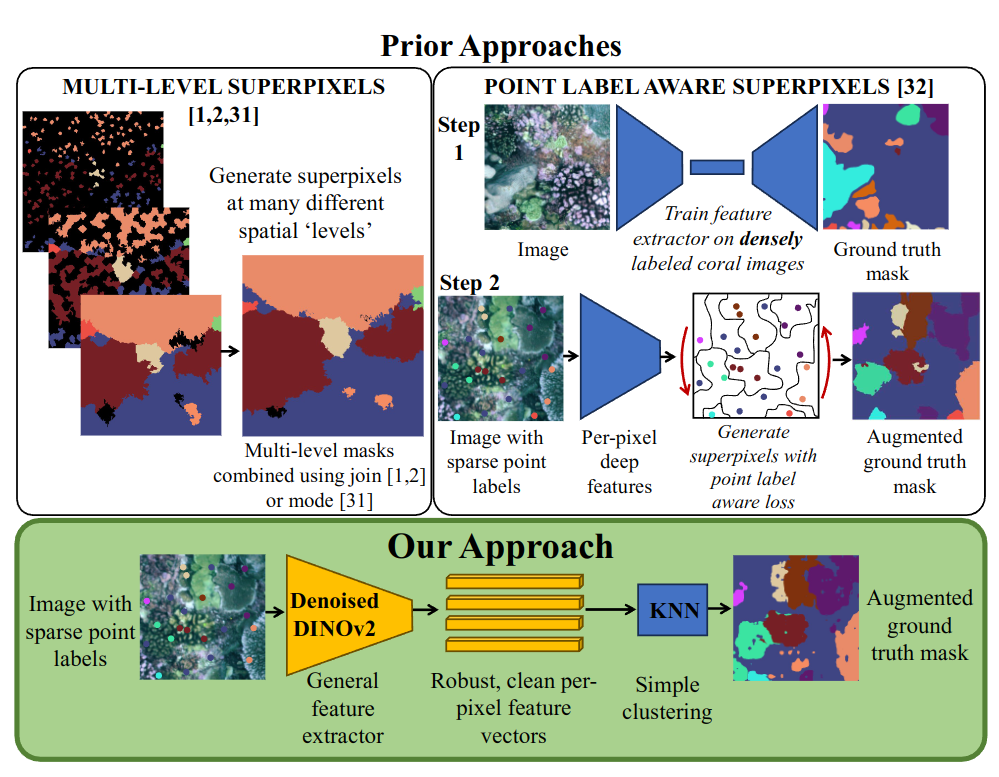 We first demonstrate that recent advances in foundation models enable generation of multi-species coral augmented ground truth masks using denoised DINOv2 features and K-Nearest Neighbors (KNN), without the need for any pre-training or custom-designed algorithms. For extremely sparsely labeled images, we propose a labeling regime based on human-in-the-loop principles, resulting in significant improvement in annotation efficiency.
[arXiv]
We first demonstrate that recent advances in foundation models enable generation of multi-species coral augmented ground truth masks using denoised DINOv2 features and K-Nearest Neighbors (KNN), without the need for any pre-training or custom-designed algorithms. For extremely sparsely labeled images, we propose a labeling regime based on human-in-the-loop principles, resulting in significant improvement in annotation efficiency.
[arXiv]
arXiv Preprints
-
Reducing Label Dependency for Underwater Scene Understanding: A Survey of Datasets, Techniques and Applications arXiv preprint arXiv:2411.11287, 2024.
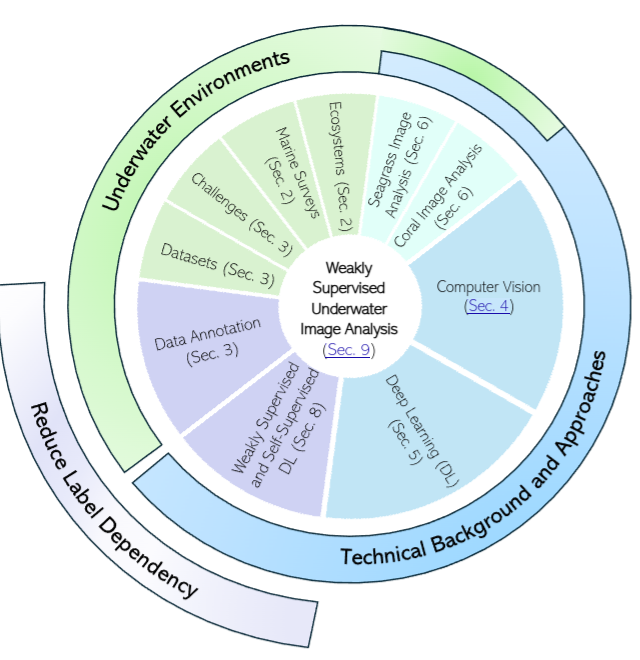 The complexity of underwater images, coupled with the specialist expertise needed to accurately identify species at the pixel level, makes the labeling process costly, time-consuming, and heavily dependent on domain experts. In recent years, some works have performed automated analysis of underwater imagery, and a smaller number of studies have focused on weakly supervised approaches which aim to reduce the expert-provided labelled data required. This survey focuses on approaches which reduce dependency on human expert input, while reviewing the prior and related approaches to position these works in the wider field of underwater perception. Further, we offer an overview of coastal ecosystems and the challenges of underwater imagery.
[arXiv]
The complexity of underwater images, coupled with the specialist expertise needed to accurately identify species at the pixel level, makes the labeling process costly, time-consuming, and heavily dependent on domain experts. In recent years, some works have performed automated analysis of underwater imagery, and a smaller number of studies have focused on weakly supervised approaches which aim to reduce the expert-provided labelled data required. This survey focuses on approaches which reduce dependency on human expert input, while reviewing the prior and related approaches to position these works in the wider field of underwater perception. Further, we offer an overview of coastal ecosystems and the challenges of underwater imagery.
[arXiv]
-
Open-Vocabulary Part-Based Grasping arXiv preprint arXiv:2406.05951, 2024.
 Many robotic applications require to grasp objects
not arbitrarily but at a very specific object part. This is especially
important for manipulation tasks beyond simple pick-and-place
scenarios or in robot-human interactions, such as object handovers. We propose AnyPart, a practical system that combines
open-vocabulary object detection, open-vocabulary part segmentation and 6DOF grasp pose prediction to infer a grasp pose on
a specific part of an object in 800 milliseconds. We contribute
two new datasets for the task of open-vocabulary part-based
grasping, a hand-segmented dataset containing 1014 object-part
segmentations, and a dataset of real-world scenarios gathered
during our robot trials for individual objects and table-clearing
tasks. We evaluate AnyPart on a mobile manipulator robot using
a set of 28 common household objects over 360 grasping trials.
AnyPart is capable of producing successful grasps 69.52 %, when
ignoring robot-based grasp failures, AnyPart predicts a grasp
location on the correct part 88.57% of the time.
[arXiv]
Many robotic applications require to grasp objects
not arbitrarily but at a very specific object part. This is especially
important for manipulation tasks beyond simple pick-and-place
scenarios or in robot-human interactions, such as object handovers. We propose AnyPart, a practical system that combines
open-vocabulary object detection, open-vocabulary part segmentation and 6DOF grasp pose prediction to infer a grasp pose on
a specific part of an object in 800 milliseconds. We contribute
two new datasets for the task of open-vocabulary part-based
grasping, a hand-segmented dataset containing 1014 object-part
segmentations, and a dataset of real-world scenarios gathered
during our robot trials for individual objects and table-clearing
tasks. We evaluate AnyPart on a mobile manipulator robot using
a set of 28 common household objects over 360 grasping trials.
AnyPart is capable of producing successful grasps 69.52 %, when
ignoring robot-based grasp failures, AnyPart predicts a grasp
location on the correct part 88.57% of the time.
[arXiv]
2023
Journal Articles
-
Bayesian Controller Fusion: Leveraging Control Priors in Deep Reinforcement Learning for Robotics The International Journal of Robotics Research (IJRR), 2023.
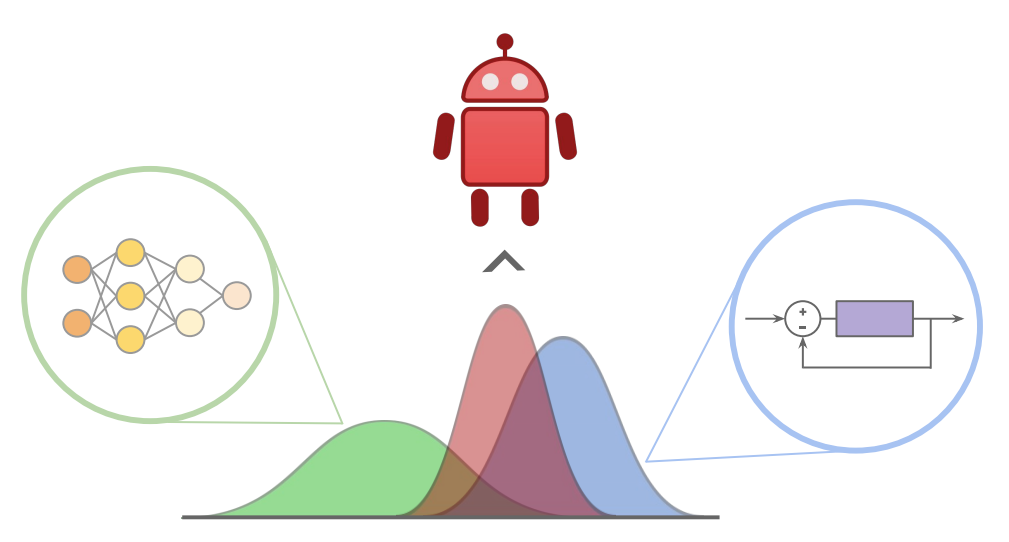 We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths.
As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience.
More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy.
We additionally show BCF’s applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real-world.
BCF is a promising approach for combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently.
[arXiv]
[website]
We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths.
As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience.
More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy.
We additionally show BCF’s applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real-world.
BCF is a promising approach for combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently.
[arXiv]
[website]
Conference Publications
-
Sayplan: Grounding Large Language Models Using 3d Scene Graphs for Scalable Robot Task Planning In Conference on Robot Learning (CoRL), 2023. Oral Presentation
 We introduce SayPlan, a scalable approach to LLM-based,
large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical
nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant
subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the
planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback
from a scene graph simulator, correcting infeasible actions and avoiding planning
failures. We evaluate our approach on two large-scale environments spanning up
to 3 floors and 36 rooms with 140 assets and objects and show that our approach is
capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute.
[arXiv]
[website]
We introduce SayPlan, a scalable approach to LLM-based,
large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical
nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant
subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the
planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback
from a scene graph simulator, correcting infeasible actions and avoiding planning
failures. We evaluate our approach on two large-scale environments spanning up
to 3 floors and 36 rooms with 140 assets and objects and show that our approach is
capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute.
[arXiv]
[website]
-
SAFE: Sensitivity-Aware Features for Out-of-Distribution Object Detection In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023.
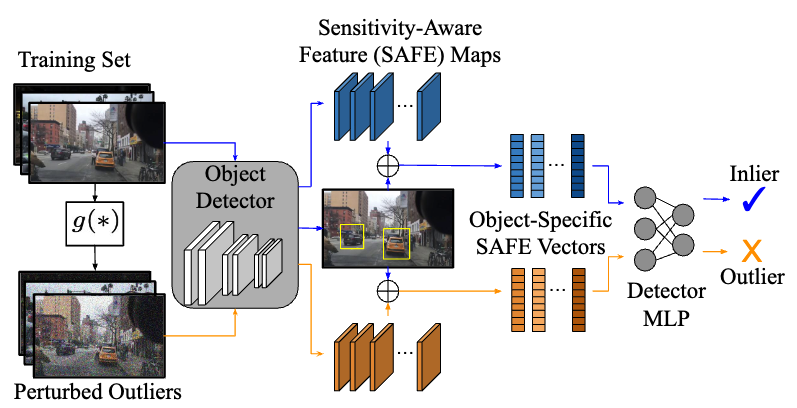 We address the problem of out-of-distribution (OOD)
detection for the task of object detection. We show that
residual convolutional layers with batch normalisation produce Sensitivity-Aware FEatures (SAFE) that are consistently powerful for distinguishing in-distribution from outof-distribution detections. We extract SAFE vectors for every detected object, and train a multilayer perceptron on
the surrogate task of distinguishing adversarially perturbed
from clean in-distribution examples. This circumvents the
need for realistic OOD training data, computationally expensive generative models, or retraining of the base object detector.
[arXiv]
We address the problem of out-of-distribution (OOD)
detection for the task of object detection. We show that
residual convolutional layers with batch normalisation produce Sensitivity-Aware FEatures (SAFE) that are consistently powerful for distinguishing in-distribution from outof-distribution detections. We extract SAFE vectors for every detected object, and train a multilayer perceptron on
the surrogate task of distinguishing adversarially perturbed
from clean in-distribution examples. This circumvents the
need for realistic OOD training data, computationally expensive generative models, or retraining of the base object detector.
[arXiv]
-
Density-aware NeRF Ensembles: Quantifying Predictive Uncertainty in Neural Radiance Fields In IEEE Conference on Robotics and Automation (ICRA), 2023.
 We show that ensembling effectively quantifies
model uncertainty in Neural Radiance Fields (NeRFs) if a
density-aware epistemic uncertainty term is considered. The
naive ensembles investigated in prior work simply average
rendered RGB images to quantify the model uncertainty caused
by conflicting explanations of the observed scene. In contrast,
we additionally consider the termination probabilities along
individual rays to identify epistemic model uncertainty due to
a lack of knowledge about the parts of a scene unobserved
during training. We achieve new state-of-the-art performance
across established uncertainty quantification benchmarks for
NeRFs, outperforming methods that require complex changes
to the NeRF architecture and training regime. We furthermore
demonstrate that NeRF uncertainty can be utilised for next-best
view selection and model refinement.
[arXiv]
We show that ensembling effectively quantifies
model uncertainty in Neural Radiance Fields (NeRFs) if a
density-aware epistemic uncertainty term is considered. The
naive ensembles investigated in prior work simply average
rendered RGB images to quantify the model uncertainty caused
by conflicting explanations of the observed scene. In contrast,
we additionally consider the termination probabilities along
individual rays to identify epistemic model uncertainty due to
a lack of knowledge about the parts of a scene unobserved
during training. We achieve new state-of-the-art performance
across established uncertainty quantification benchmarks for
NeRFs, outperforming methods that require complex changes
to the NeRF architecture and training regime. We furthermore
demonstrate that NeRF uncertainty can be utilised for next-best
view selection and model refinement.
[arXiv]
-
Hyperdimensional Feature Fusion for Out-Of-Distribution Detection In IEEE Winter Conference on Applications of Computer Vision (WACV), 2023.
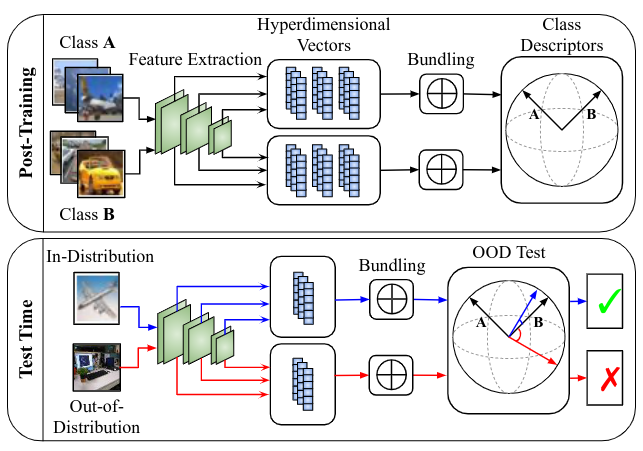 We introduce powerful ideas from Hyperdimensional
Computing into the challenging field of Out-of-Distribution
(OOD) detection. In contrast to most existing works that perform OOD detection based on only a single layer of a neural
network, we use similarity-preserving semi-orthogonal projection matrices to project the feature maps from multiple
layers into a common vector space. By repeatedly applying the bundling operation ⊕, we create expressive classspecific descriptor vectors for all in-distribution classes.
[arXiv]
We introduce powerful ideas from Hyperdimensional
Computing into the challenging field of Out-of-Distribution
(OOD) detection. In contrast to most existing works that perform OOD detection based on only a single layer of a neural
network, we use similarity-preserving semi-orthogonal projection matrices to project the feature maps from multiple
layers into a common vector space. By repeatedly applying the bundling operation ⊕, we create expressive classspecific descriptor vectors for all in-distribution classes.
[arXiv]
Workshop Publications
-
Physically Embodied Gaussian Splatting: Embedding Physical Priors Into a Visual 3d World Model for Robotics In Workshop for Neural Representation Learning for Robot Manipulation, Conference on Robot Learning (CoRL), 2023.
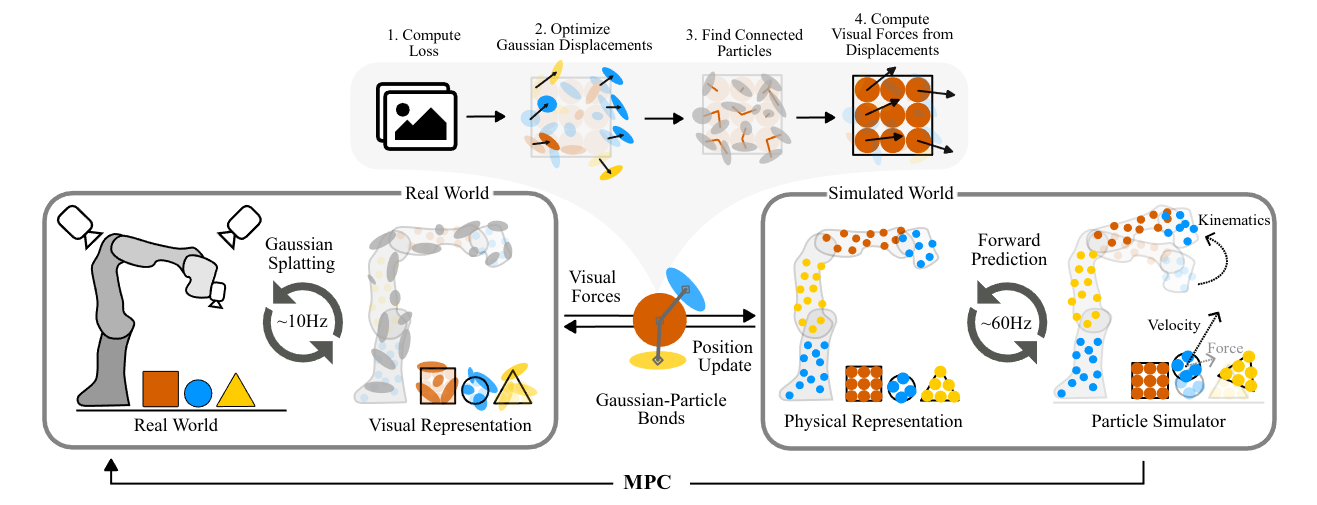 Our dual Gaussian-Particle representation captures visual (Gaussians) and physical (particles) aspects of the world and enables forward prediction of robot interactions with the world.
A photometric loss between rendered Gaussians and observed images is computed (Gaussian Splatting) and converted into visual forces. These and other physical phenomena such as gravity, collisions, and mechanical forces are resolved by the always-active physics system and applied to the particles, which in turn influence the position of their associated Gaussians.
[website]
Our dual Gaussian-Particle representation captures visual (Gaussians) and physical (particles) aspects of the world and enables forward prediction of robot interactions with the world.
A photometric loss between rendered Gaussians and observed images is computed (Gaussian Splatting) and converted into visual forces. These and other physical phenomena such as gravity, collisions, and mechanical forces are resolved by the always-active physics system and applied to the particles, which in turn influence the position of their associated Gaussians.
[website]
-
The Need for Inherently Privacy-Preserving Vision in Trustworthy Autonomous Systems In ICRA Workshop on Multidisciplinary Approaches to Co-Creating Trustworthy Autonomous Systems, 2023. Best Poster Award
 This paper is a call to action to consider privacy
in the context of robotic vision. We propose a specific form
privacy preservation in which no images are captured or could
be reconstructed by an attacker even with full remote access.
We present a set of principles by which such systems can be
designed, and through a case study in localisation demonstrate
in simulation a specific implementation that delivers an important robotic capability in an inherently privacy-preserving
manner. This is a first step, and we hope to inspire future works
that expand the range of applications open to sighted robotic
systems.
[arXiv]
This paper is a call to action to consider privacy
in the context of robotic vision. We propose a specific form
privacy preservation in which no images are captured or could
be reconstructed by an attacker even with full remote access.
We present a set of principles by which such systems can be
designed, and through a case study in localisation demonstrate
in simulation a specific implementation that delivers an important robotic capability in an inherently privacy-preserving
manner. This is a first step, and we hope to inspire future works
that expand the range of applications open to sighted robotic
systems.
[arXiv]
-
Contrastive Language, Action, and State Pre-training for Robot Learning In ICRA Workshop on Pretraining for Robotics (PT4R), 2023.
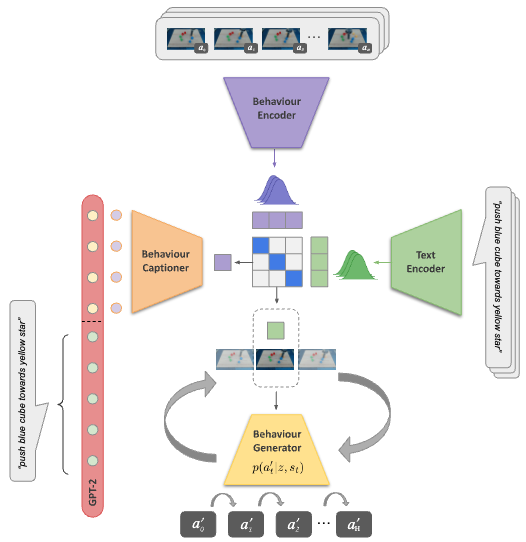 We introduce a method for unifying language, action, and state information in a shared embedding space to facilitate a range of downstream tasks in robot learning. Our method, Contrastive Language, Action, and State Pre-training (CLASP), extends the CLIP formulation by incorporating distributional learning, capturing the inherent complexities and one-to-many relationships in behaviour-text alignment. By employing distributional outputs for both text and behaviour encoders, our model effectively associates diverse textual commands with a single behaviour and vice-versa. We demonstrate the utility of our method for the following downstream tasks: zero-shot text-behaviour retrieval, captioning unseen robot behaviours, and learning a behaviour prior for language-conditioned reinforcement learning.
[arXiv]
We introduce a method for unifying language, action, and state information in a shared embedding space to facilitate a range of downstream tasks in robot learning. Our method, Contrastive Language, Action, and State Pre-training (CLASP), extends the CLIP formulation by incorporating distributional learning, capturing the inherent complexities and one-to-many relationships in behaviour-text alignment. By employing distributional outputs for both text and behaviour encoders, our model effectively associates diverse textual commands with a single behaviour and vice-versa. We demonstrate the utility of our method for the following downstream tasks: zero-shot text-behaviour retrieval, captioning unseen robot behaviours, and learning a behaviour prior for language-conditioned reinforcement learning.
[arXiv]
arXiv Preprints
-
LHManip: A Dataset for Long-Horizon Language-Grounded Manipulation Tasks in Cluttered Tabletop Environments arXiv preprint arXiv:2312.12036, 2023.
 We present the Long-Horizon Manipulation (LHManip) dataset comprising 200
episodes, demonstrating 20 different manipulation tasks via real robot teleoperation. The tasks entail multiple sub-tasks,
including grasping, pushing, stacking and throwing objects in highly cluttered environments. Each task is paired with a
natural language instruction and multi-camera viewpoints for point-cloud or NeRF reconstruction. In total, the dataset
comprises 176,278 observation-action pairs which form part of the Open X-Embodiment dataset.
[arXiv]
[website]
We present the Long-Horizon Manipulation (LHManip) dataset comprising 200
episodes, demonstrating 20 different manipulation tasks via real robot teleoperation. The tasks entail multiple sub-tasks,
including grasping, pushing, stacking and throwing objects in highly cluttered environments. Each task is paired with a
natural language instruction and multi-camera viewpoints for point-cloud or NeRF reconstruction. In total, the dataset
comprises 176,278 observation-action pairs which form part of the Open X-Embodiment dataset.
[arXiv]
[website]
2022
Journal Articles
-
A Holistic Approach to Reactive Mobile Manipulation IEEE Robotics and Automation Letters, 2022.
 We present the design and implementation of a taskable reactive mobile manipulation system. In contrary to related work, we treat the arm and base degrees of freedom as a holistic structure which greatly improves the speed and fluidity of the resulting motion. At the core of this approach is a robust and reactive motion controller which can achieve a desired end-effector pose, while avoiding joint position and velocity limits, and ensuring the mobile manipulator is manoeuvrable throughout the trajectory. This can support sensor-based behaviours such as closed-loop visual grasping. As no planning is involved in our approach, the robot is never stationary thinking about what to do next. We show the versatility of our holistic motion controller by implementing a pick and place system using behaviour trees and demonstrate this task on a 9-degree-of-freedom mobile manipulator.
[arXiv]
[website]
We present the design and implementation of a taskable reactive mobile manipulation system. In contrary to related work, we treat the arm and base degrees of freedom as a holistic structure which greatly improves the speed and fluidity of the resulting motion. At the core of this approach is a robust and reactive motion controller which can achieve a desired end-effector pose, while avoiding joint position and velocity limits, and ensuring the mobile manipulator is manoeuvrable throughout the trajectory. This can support sensor-based behaviours such as closed-loop visual grasping. As no planning is involved in our approach, the robot is never stationary thinking about what to do next. We show the versatility of our holistic motion controller by implementing a pick and place system using behaviour trees and demonstrate this task on a 9-degree-of-freedom mobile manipulator.
[arXiv]
[website]
-
BenchBot environments for active robotics (BEAR): Simulated data for active scene understanding research The International Journal of Robotics Research, 2022.
 We present a platform to foster research in active scene understanding, consisting of high-fidelity simulated environments and a simple yet powerful API that controls a mobile robot in simulation and reality. In contrast to static, pre-recorded datasets that focus on the perception aspect of scene understanding, agency is a top priority in our work. We provide three levels of robot agency, allowing users to control a robot at varying levels of difficulty and realism. While the most basic level provides pre-defined trajectories and ground-truth localisation, the more realistic levels allow us to evaluate integrated behaviours comprising perception, navigation, exploration and SLAM.
[website]
We present a platform to foster research in active scene understanding, consisting of high-fidelity simulated environments and a simple yet powerful API that controls a mobile robot in simulation and reality. In contrast to static, pre-recorded datasets that focus on the perception aspect of scene understanding, agency is a top priority in our work. We provide three levels of robot agency, allowing users to control a robot at varying levels of difficulty and realism. While the most basic level provides pre-defined trajectories and ground-truth localisation, the more realistic levels allow us to evaluate integrated behaviours comprising perception, navigation, exploration and SLAM.
[website]
-
FSNet: A Failure Detection Framework for Semantic Segmentation IEEE Robotics and Automation Letters, 2022.
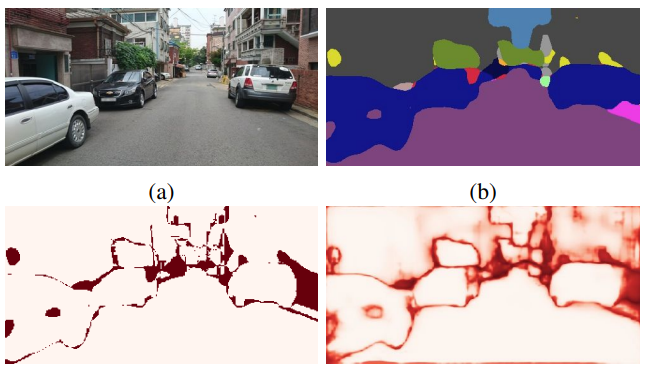 Semantic segmentation is an important task that helps autonomous vehicles understand their surroundings and navigate safely. However, during deployment, even the most mature segmentation models are vulnerable to various external factors that can degrade the segmentation performance with potentially catastrophic consequences for the vehicle and its surroundings. To address this issue, we propose a failure detection framework to identify pixel-level misclassification. We do so by exploiting internal features of the segmentation model and training it simultaneously with a failure detection network. During deployment, the failure detector flags areas in the image where the segmentation model has failed to segment correctly.
[arXiv]
Semantic segmentation is an important task that helps autonomous vehicles understand their surroundings and navigate safely. However, during deployment, even the most mature segmentation models are vulnerable to various external factors that can degrade the segmentation performance with potentially catastrophic consequences for the vehicle and its surroundings. To address this issue, we propose a failure detection framework to identify pixel-level misclassification. We do so by exploiting internal features of the segmentation model and training it simultaneously with a failure detection network. During deployment, the failure detector flags areas in the image where the segmentation model has failed to segment correctly.
[arXiv]
-
Semantic–geometric visual place recognition: a new perspective for reconciling opposing views The International Journal of Robotics Research (IJRR), 2022.
 We propose a hybrid image descriptor that semantically aggregates salient visual information, complemented by appearance-based description, and augment a conventional coarse-to-fine recognition pipeline with keypoint correspondences extracted from within the convolutional feature maps of a pre-trained network. Finally, we introduce descriptor normalization and local score enhancement strategies for improving the robustness of the system. Using both existing benchmark datasets and extensive new datasets that for the first time combine the three challenges of opposing viewpoints, lateral viewpoint shifts, and extreme appearance change, we show that our system can achieve practical place recognition performance where existing state-of-the-art methods fail.
We propose a hybrid image descriptor that semantically aggregates salient visual information, complemented by appearance-based description, and augment a conventional coarse-to-fine recognition pipeline with keypoint correspondences extracted from within the convolutional feature maps of a pre-trained network. Finally, we introduce descriptor normalization and local score enhancement strategies for improving the robustness of the system. Using both existing benchmark datasets and extensive new datasets that for the first time combine the three challenges of opposing viewpoints, lateral viewpoint shifts, and extreme appearance change, we show that our system can achieve practical place recognition performance where existing state-of-the-art methods fail.
Conference Publications
-
Residual Skill Policies: Learning an Adaptable Skill-based Action Space for Reinforcement Learning for Robotics In Conference on Robot Learning (CoRL), 2022.
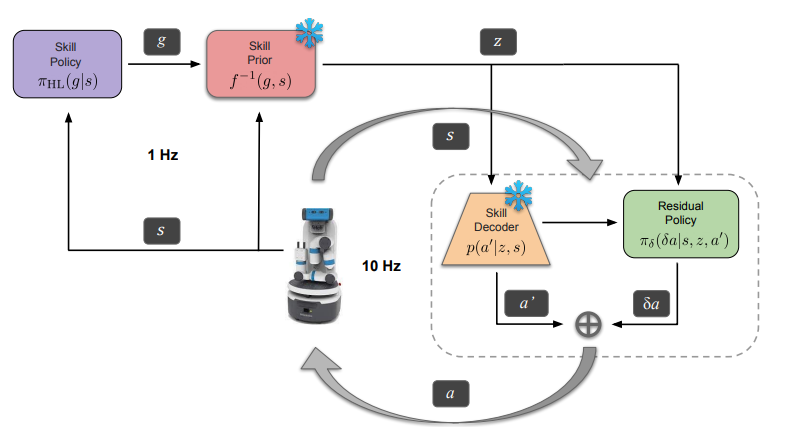 Skill-based reinforcement learning (RL) has emerged as a promising strategy to
leverage prior knowledge for accelerated robot learning. We firstly
propose accelerating exploration in the skill space using state-conditioned generative models to directly bias the high-level agent towards only sampling skills
relevant to a given state based on prior experience. Next, we propose a low-level
residual policy for fine-grained skill adaptation enabling downstream RL agents
to adapt to unseen task variations. Finally, we validate our approach across four
challenging manipulation tasks that differ from those used to build the skill space,
demonstrating our ability to learn across task variations while significantly accelerating exploration, outperforming prior works.
[arXiv]
[website]
Skill-based reinforcement learning (RL) has emerged as a promising strategy to
leverage prior knowledge for accelerated robot learning. We firstly
propose accelerating exploration in the skill space using state-conditioned generative models to directly bias the high-level agent towards only sampling skills
relevant to a given state based on prior experience. Next, we propose a low-level
residual policy for fine-grained skill adaptation enabling downstream RL agents
to adapt to unseen task variations. Finally, we validate our approach across four
challenging manipulation tasks that differ from those used to build the skill space,
demonstrating our ability to learn across task variations while significantly accelerating exploration, outperforming prior works.
[arXiv]
[website]
-
Forest Traversability Mapping (FTM): Traversability estimation using 3D voxel-based Normal Distributed Transform to enable forest navigation In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022.
 Autonomous navigation in dense vegetation remains an open challenge and is an area of major interest for the research community. In this paper we propose a novel traversability estimation method, the Forest Traversability Map, that gives autonomous ground vehicles the ability to navigate in harsh forests or densely vegetated environments. The method estimates travers ability in unstructured environments dominated by vegetation, void of any dominant human structures, gravel or dirt roads, with higher accuracy than the state of the art.
Autonomous navigation in dense vegetation remains an open challenge and is an area of major interest for the research community. In this paper we propose a novel traversability estimation method, the Forest Traversability Map, that gives autonomous ground vehicles the ability to navigate in harsh forests or densely vegetated environments. The method estimates travers ability in unstructured environments dominated by vegetation, void of any dominant human structures, gravel or dirt roads, with higher accuracy than the state of the art.
Workshop Publications
-
Implicit Object Mapping With Noisy Data In RSS Workshop on Implicit Representations for Robotic Manipulation, 2022.
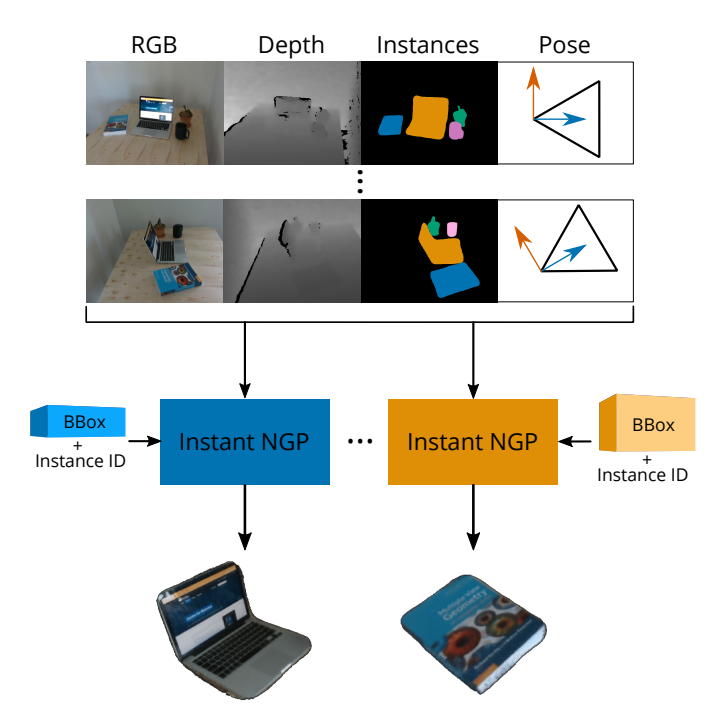 This paper uses the outputs of an object-based SLAM system to bound objects in the scene with coarse primitives and - in concert with instance masks - identify obstructions in the training images. Objects are therefore automatically bounded, and non-relevant geometry is excluded from the NeRF representation. The method’s performance is benchmarked under ideal conditions and tested against errors in the poses and instance masks. Our results show that object-based NeRFs are robust to pose variations but sensitive to the quality of the instance masks.
[arXiv]
This paper uses the outputs of an object-based SLAM system to bound objects in the scene with coarse primitives and - in concert with instance masks - identify obstructions in the training images. Objects are therefore automatically bounded, and non-relevant geometry is excluded from the NeRF representation. The method’s performance is benchmarked under ideal conditions and tested against errors in the poses and instance masks. Our results show that object-based NeRFs are robust to pose variations but sensitive to the quality of the instance masks.
[arXiv]
arXiv Preprints
-
Retrospectives on the Embodied AI Workshop arXiv preprint arXiv:2210.06849, 2022.
 We present a retrospective on the state of Embodied AI
research. Our analysis focuses on 13 challenges presented
at the Embodied AI Workshop at CVPR. These challenges
are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We
discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of stateof-the-art models. We highlight commonalities between top
approaches to the challenges and identify potential future
directions for Embodied AI research.
[arXiv]
We present a retrospective on the state of Embodied AI
research. Our analysis focuses on 13 challenges presented
at the Embodied AI Workshop at CVPR. These challenges
are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We
discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of stateof-the-art models. We highlight commonalities between top
approaches to the challenges and identify potential future
directions for Embodied AI research.
[arXiv]
2021
Journal Articles
-
Uncertainty for Identifying Open-Set Errors in Visual Object Detection IEEE Robotics and Automation Letters (RA-L), 2021.
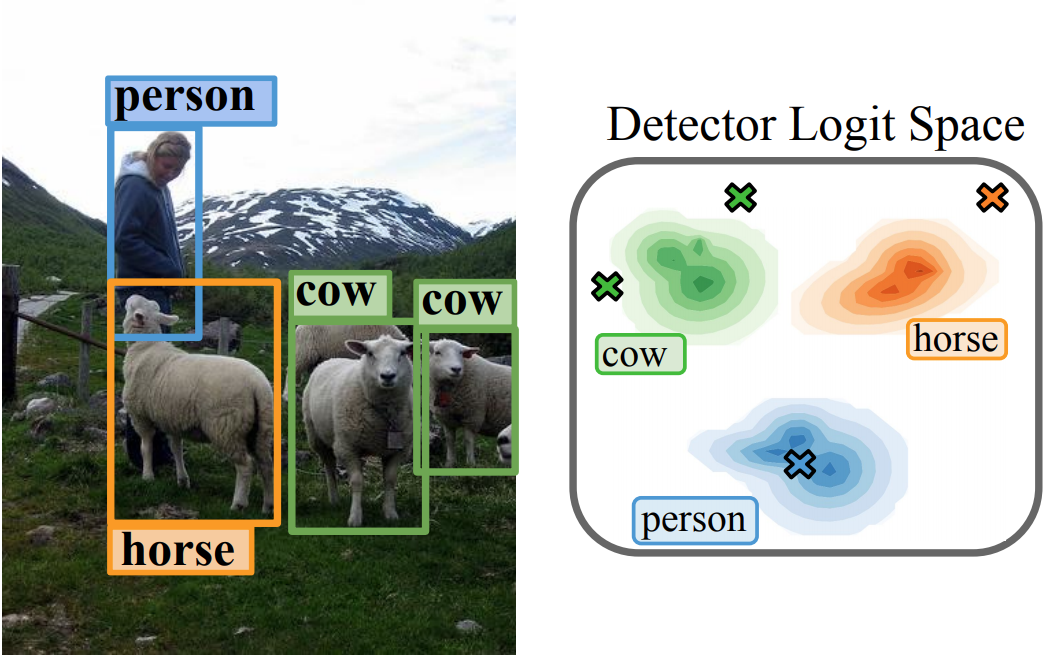 We propose GMM-Det, a real-time method for extracting
epistemic uncertainty from object detectors to identify and reject open-set errors. GMM-Det trains the detector to produce a
structured logit space that is modelled with class-specific Gaussian Mixture Models. At test time, open-set errors are identified
by their low log-probability under all Gaussian Mixture Models.
We test two common detector architectures, Faster R-CNN and
RetinaNet, across three varied datasets spanning robotics and
computer vision. Our results show that GMM-Det consistently
outperforms existing uncertainty techniques for identifying and
rejecting open-set detections, especially at the low-error-rate
operating point required for safety-critical applications. GMMDet maintains object detection performance, and introduces
only minimal computational overhead.
[arXiv]
We propose GMM-Det, a real-time method for extracting
epistemic uncertainty from object detectors to identify and reject open-set errors. GMM-Det trains the detector to produce a
structured logit space that is modelled with class-specific Gaussian Mixture Models. At test time, open-set errors are identified
by their low log-probability under all Gaussian Mixture Models.
We test two common detector architectures, Faster R-CNN and
RetinaNet, across three varied datasets spanning robotics and
computer vision. Our results show that GMM-Det consistently
outperforms existing uncertainty techniques for identifying and
rejecting open-set detections, especially at the low-error-rate
operating point required for safety-critical applications. GMMDet maintains object detection performance, and introduces
only minimal computational overhead.
[arXiv]
-
Semantics for robotic mapping, perception and interaction: A survey Foundations and Trends in Robotics, 2021.
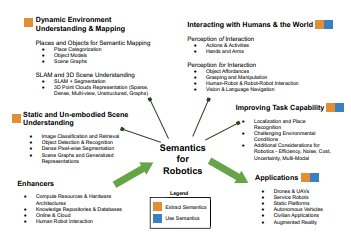 This survey provides an overarching snapshot of where semantics in robotics stands today. We establish a taxonomy for semantics research in or relevant to robotics, split into four broad categories of activity, in which semantics are extracted, used, or both. Within these broad categories we survey dozens of major topics including fundamentals from the computer vision field and key robotics research areas utilizing semantics, including mapping, navigation and interaction with the world. The survey also covers key practical considerations, including enablers like increased data availability and improved computational hardware, and major application areas where semantics is or is likely to play a key role. In creating this survey, we hope to provide researchers across academia and industry with a comprehensive reference that helps facilitate future research in this exciting field.
[arXiv]
This survey provides an overarching snapshot of where semantics in robotics stands today. We establish a taxonomy for semantics research in or relevant to robotics, split into four broad categories of activity, in which semantics are extracted, used, or both. Within these broad categories we survey dozens of major topics including fundamentals from the computer vision field and key robotics research areas utilizing semantics, including mapping, navigation and interaction with the world. The survey also covers key practical considerations, including enablers like increased data availability and improved computational hardware, and major application areas where semantics is or is likely to play a key role. In creating this survey, we hope to provide researchers across academia and industry with a comprehensive reference that helps facilitate future research in this exciting field.
[arXiv]
-
Probabilistic Appearance-Invariant Topometric Localization with New Place Awareness IEEE Robotics and Automation Letters (RA-L), 2021.
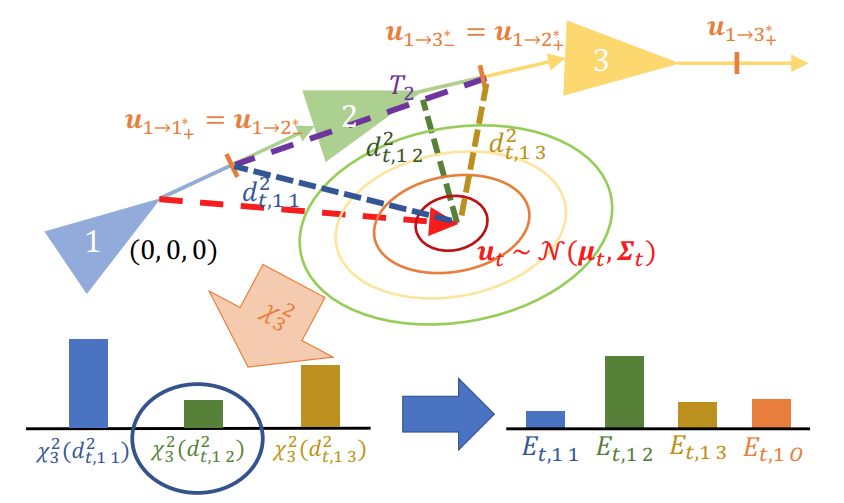 We present a new probabilistic topometric localization system which incorporates full 3-dof odometry into the motion model and furthermore, adds an “off-map” state within the state-estimation framework, allowing query traverses which feature significant route detours from the reference map to be successfully localized. We perform extensive evaluation on multiple query traverses from the Oxford RobotCar dataset exhibiting both significant appearance change and deviations from routes previously traversed.
[arXiv]
We present a new probabilistic topometric localization system which incorporates full 3-dof odometry into the motion model and furthermore, adds an “off-map” state within the state-estimation framework, allowing query traverses which feature significant route detours from the reference map to be successfully localized. We perform extensive evaluation on multiple query traverses from the Oxford RobotCar dataset exhibiting both significant appearance change and deviations from routes previously traversed.
[arXiv]
-
Probabilistic Visual Place Recognition for Hierarchical Localization IEEE Robotics and Automation Letters (RA-L), 2021.
 We propose two methods which adapt image retrieval techniques used for visual place recognition to the Bayesian state estimation formulation for localization. We demonstrate significant improvements to the
localization accuracy of the coarse localization stage using our methods, whilst retaining state-of-the-art performance under severe appearance change. Using extensive experimentation on the Oxford RobotCar dataset, results show that our approach
outperforms comparable state-of-the-art methods in terms of precision-recall performance for localizing image sequences. In addition, our proposed methods provides the flexibility
to contextually scale localization latency in order to achieve these improvements.
[arXiv]
We propose two methods which adapt image retrieval techniques used for visual place recognition to the Bayesian state estimation formulation for localization. We demonstrate significant improvements to the
localization accuracy of the coarse localization stage using our methods, whilst retaining state-of-the-art performance under severe appearance change. Using extensive experimentation on the Oxford RobotCar dataset, results show that our approach
outperforms comparable state-of-the-art methods in terms of precision-recall performance for localizing image sequences. In addition, our proposed methods provides the flexibility
to contextually scale localization latency in order to achieve these improvements.
[arXiv]
Conference Publications
-
VarifocalNet: An IoU-aware Dense Object Detector In Conference on Computer Vision and Pattern Recognition (CVPR), 2021. Oral Presentation
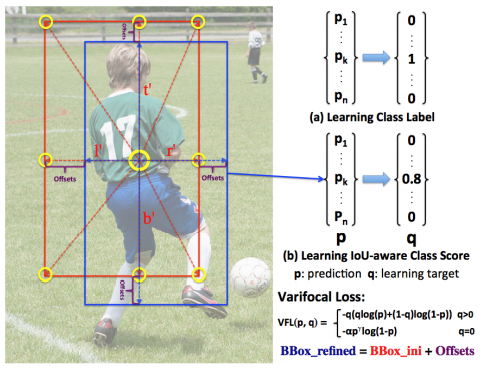 Accurately ranking the vast number of candidate detections is crucial for dense object detectors to achieve high performance. Prior work uses the classification score or a combination of classification and predicted localization scores to rank candidates. However, neither option results in a reliable ranking, thus degrading detection performance. In this paper, we propose to learn an Iou-aware Classification Score (IACS) as a joint representation of object presence confidence and localization accuracy. We show that dense object detectors can achieve a more accurate ranking of candidate detections based on the IACS. We design a new loss function, named Varifocal Loss, to train a dense object detector to predict the IACS, and propose a new star-shaped bounding box feature representation for IACS prediction and bounding box refinement. Combining these two new components and a bounding box refinement branch, we build an IoU-aware dense object detector based on the FCOS+ATSS architecture, that we call VarifocalNet or VFNet for short.
[arXiv]
[website]
Accurately ranking the vast number of candidate detections is crucial for dense object detectors to achieve high performance. Prior work uses the classification score or a combination of classification and predicted localization scores to rank candidates. However, neither option results in a reliable ranking, thus degrading detection performance. In this paper, we propose to learn an Iou-aware Classification Score (IACS) as a joint representation of object presence confidence and localization accuracy. We show that dense object detectors can achieve a more accurate ranking of candidate detections based on the IACS. We design a new loss function, named Varifocal Loss, to train a dense object detector to predict the IACS, and propose a new star-shaped bounding box feature representation for IACS prediction and bounding box refinement. Combining these two new components and a bounding box refinement branch, we build an IoU-aware dense object detector based on the FCOS+ATSS architecture, that we call VarifocalNet or VFNet for short.
[arXiv]
[website]
-
Online Monitoring of Object Detection Performance Post-Deployment In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2021.
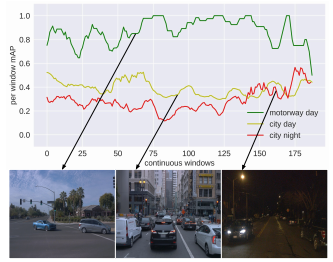 Post-deployment, an object detector is expected to operate at a similar level of performance that was reported on its testing dataset. However, when deployed onboard mobile robots that operate under varying and complex environmental conditions, the detector’s performance can fluctuate and occasionally degrade severely without warning. Undetected, this can lead the robot to take unsafe and risky actions based on low-quality and unreliable object detections. We address this problem and introduce a cascaded neural network that monitors the performance of the object detector by predicting the quality of its mean average precision (mAP) on a sliding window of the input frames.
[arXiv]
Post-deployment, an object detector is expected to operate at a similar level of performance that was reported on its testing dataset. However, when deployed onboard mobile robots that operate under varying and complex environmental conditions, the detector’s performance can fluctuate and occasionally degrade severely without warning. Undetected, this can lead the robot to take unsafe and risky actions based on low-quality and unreliable object detections. We address this problem and introduce a cascaded neural network that monitors the performance of the object detector by predicting the quality of its mean average precision (mAP) on a sliding window of the input frames.
[arXiv]
-
Evaluating the Impact of Semantic Segmentation and Pose Estimationon Dense Semantic SLAM In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2021.
 Recent Semantic SLAM methods combine classical geometry-based estimation with deep learning-based object detection or semantic segmentation.
In this paper we evaluate the quality of semantic maps generated by state-of-the-art class- and instance-aware dense semantic SLAM algorithms whose codes are publicly available and explore the impacts both semantic segmentation and pose estimation have on the quality of semantic maps.
We obtain these results by providing algorithms with ground-truth pose and/or semantic segmentation data available from simulated environments. We establish that semantic segmentation is the largest source of error through our experiments, dropping mAP and OMQ performance by up to 74.3% and 71.3% respectively.
Recent Semantic SLAM methods combine classical geometry-based estimation with deep learning-based object detection or semantic segmentation.
In this paper we evaluate the quality of semantic maps generated by state-of-the-art class- and instance-aware dense semantic SLAM algorithms whose codes are publicly available and explore the impacts both semantic segmentation and pose estimation have on the quality of semantic maps.
We obtain these results by providing algorithms with ground-truth pose and/or semantic segmentation data available from simulated environments. We establish that semantic segmentation is the largest source of error through our experiments, dropping mAP and OMQ performance by up to 74.3% and 71.3% respectively.
-
Class Anchor Clustering: A Loss for Distance-based Open Set Recognition In IEEE Winter Conference on Applications of Computer Vision (WACV), 2021.
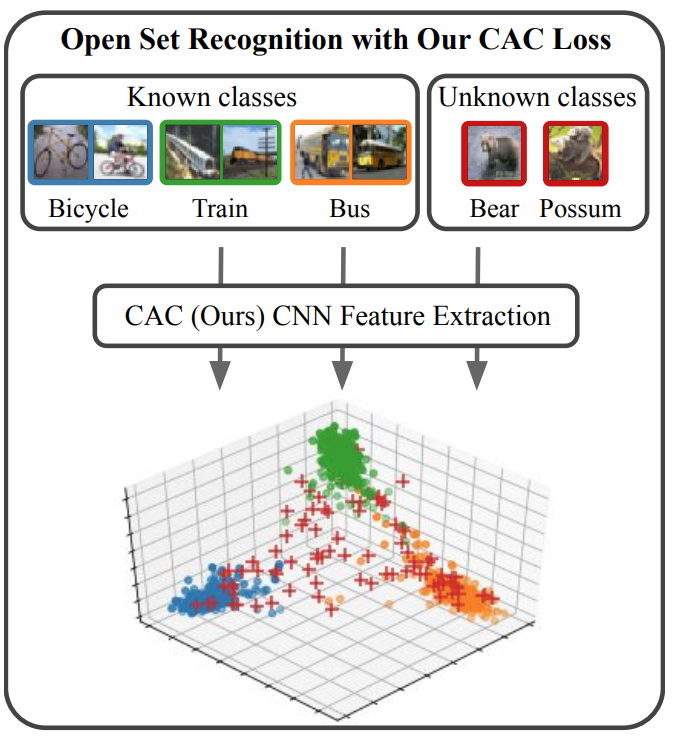 Existing open set classifiers distinguish between known and unknown inputs by measuring distance in a network’s logit space, assuming that known inputs cluster closer to the training data than unknown inputs. However, this approach is typically applied post-hoc to networks trained with cross-entropy loss, which neither guarantees nor encourages the hoped-for clustering behaviour. To overcome this limitation, we introduce Class Anchor Clustering (CAC) loss. CAC is an entirely distance-based loss that explicitly encourages training data to form tight clusters techniques on the challenging TinyImageNet dataset, achieving a 2.4% performance increase in AUROC.
[arXiv]
Existing open set classifiers distinguish between known and unknown inputs by measuring distance in a network’s logit space, assuming that known inputs cluster closer to the training data than unknown inputs. However, this approach is typically applied post-hoc to networks trained with cross-entropy loss, which neither guarantees nor encourages the hoped-for clustering behaviour. To overcome this limitation, we introduce Class Anchor Clustering (CAC) loss. CAC is an entirely distance-based loss that explicitly encourages training data to form tight clusters techniques on the challenging TinyImageNet dataset, achieving a 2.4% performance increase in AUROC.
[arXiv]
Workshop Publications
-
Zero-Shot Uncertainty-Aware Deployment of Simulation Trained Policies on Real-World Robots In NeuIPS Workshop on Deployable Decision Makig in Embodied Systems, 2021.
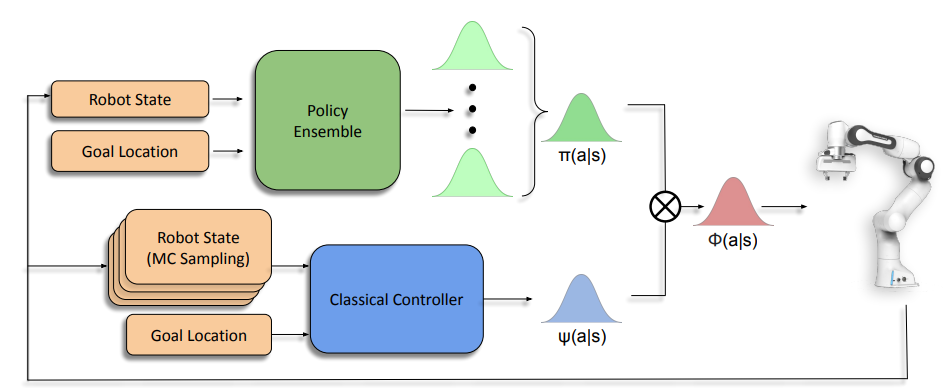 While deep reinforcement learning (RL) agents have demonstrated incredible potential in attaining dexterous behaviours for robotics, they tend to make errors when deployed in the real world due to mismatches between the training and execution environments. In contrast, the classical robotics community have developed a range of controllers that can safely operate across most states in the real world given their explicit derivation. These controllers however lack the dexterity required for complex tasks given limitations in analytical modelling and approximations. In this paper, we propose Bayesian Controller Fusion (BCF), a novel uncertainty-aware deployment strategy that combines the strengths of deep RL policies and traditional handcrafted controllers.
[arXiv]
While deep reinforcement learning (RL) agents have demonstrated incredible potential in attaining dexterous behaviours for robotics, they tend to make errors when deployed in the real world due to mismatches between the training and execution environments. In contrast, the classical robotics community have developed a range of controllers that can safely operate across most states in the real world given their explicit derivation. These controllers however lack the dexterity required for complex tasks given limitations in analytical modelling and approximations. In this paper, we propose Bayesian Controller Fusion (BCF), a novel uncertainty-aware deployment strategy that combines the strengths of deep RL policies and traditional handcrafted controllers.
[arXiv]
arXiv Preprints
2020
Journal Articles
Special Issues
-
Special Issue on Deep Learning for Robotic Vision The International Journal for Computer Vision (IJCV), 2020.
Conference Publications
-
Multiplicative Controller Fusion: Leveraging Algorithmic Priors for Sample-efficient Reinforcement Learning and Safe Sim-To-Real Transfer In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2020.
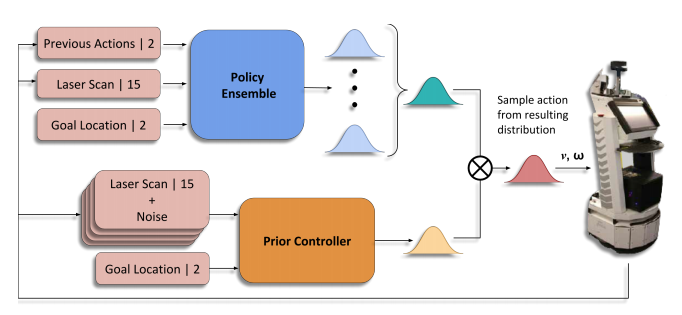 Learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior’s influence is annealed gradually. During deployment, the policy’s uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning.
[arXiv]
[website]
Learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior’s influence is annealed gradually. During deployment, the policy’s uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning.
[arXiv]
[website]
-
Residual Reactive Navigation: Combining Classical and Learned Navigation Strategies For Deployment in Unknown Environments In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2020.
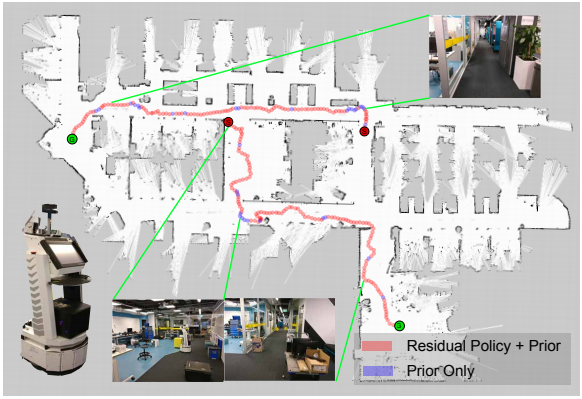 In this work we focus on improving the efficiency and generalisation of learned navigation strategies when transferred from its training environment to previously unseen ones. We present an extension of the residual reinforcement learning framework from the robotic manipulation literature and adapt it to the vast and unstructured environments that mobile robots can operate in. The concept is based on learning a residual control effect to add to a typical sub-optimal classical controller in order to close the performance gap, whilst guiding the exploration process during training for improved data efficiency. We exploit this tight coupling and propose a novel deployment strategy, switching Residual Reactive Navigation (sRNN), which yields efficient trajectories whilst probabilistically switching to a classical controller in cases of high policy uncertainty. Our approach achieves improved performance over end-to-end alternatives and can be incorporated as part of a complete navigation stack for cluttered indoor navigation tasks in the real world.
[arXiv]
[website]
In this work we focus on improving the efficiency and generalisation of learned navigation strategies when transferred from its training environment to previously unseen ones. We present an extension of the residual reinforcement learning framework from the robotic manipulation literature and adapt it to the vast and unstructured environments that mobile robots can operate in. The concept is based on learning a residual control effect to add to a typical sub-optimal classical controller in order to close the performance gap, whilst guiding the exploration process during training for improved data efficiency. We exploit this tight coupling and propose a novel deployment strategy, switching Residual Reactive Navigation (sRNN), which yields efficient trajectories whilst probabilistically switching to a classical controller in cases of high policy uncertainty. Our approach achieves improved performance over end-to-end alternatives and can be incorporated as part of a complete navigation stack for cluttered indoor navigation tasks in the real world.
[arXiv]
[website]
-
Probabilistic Object Detection: Definition and Evaluation In IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
 We introduce Probabilistic Object Detection, the task of detecting objects in images and accurately quantifying the spatial and semantic uncertainties of the detections. Given the lack of methods capable of assessing such probabilistic object detections, we present the new Probability-based Detection Quality measure (PDQ). Unlike AP-based measures, PDQ has no arbitrary thresholds and rewards spatial and label quality, and foreground/background separation quality while explicitly penalising false positive and false negative detections.
[arXiv]
We introduce Probabilistic Object Detection, the task of detecting objects in images and accurately quantifying the spatial and semantic uncertainties of the detections. Given the lack of methods capable of assessing such probabilistic object detections, we present the new Probability-based Detection Quality measure (PDQ). Unlike AP-based measures, PDQ has no arbitrary thresholds and rewards spatial and label quality, and foreground/background separation quality while explicitly penalising false positive and false negative detections.
[arXiv]
arXiv Preprints
-
Swa Object Detection arXiv preprint arXiv:2012.12645, 2020. Do you want to improve 1.0 AP for your object detector without any inference cost and any change to your detector? It is surprisingly simple: train your detector for an extra 12 epochs using cyclical learning rates and then average these 12 checkpoints as your final detection model. This potent recipe is inspired by Stochastic Weights Averaging (SWA), which is proposed in arXiv:1803.05407 for improving generalization in deep neural networks. We found it also very effective in object detection. In this technique report, we systematically investigate the effects of applying SWA to object detection as well as instance segmentation. Through extensive experiments, we discover the aforementioned workable policy of performing SWA in object detection, and we consistently achieve ∼1.0 AP improvement over various popular detectors on the challenging COCO benchmark, including Mask RCNN, Faster RCNN, RetinaNet, FCOS, YOLOv3 and VFNet. We hope this work will make more researchers in object detection know this technique and help them train better object detectors. [arXiv] [website]
-
The Robotic Vision Scene Understanding Challenge arXiv preprint arXiv:2009.05246, 2020.
 Being able to explore an environment and understand the location and type of all objects therein is important for indoor robotic platforms that must interact closely with humans. However, it is difficult to evaluate progress in this area due to a lack of standardized testing which is limited due to the need for active robot agency and perfect object ground-truth. To help provide a standard for testing scene understanding systems, we present a new robot vision scene understanding challenge using simulation to enable repeatable experiments with active robot agency. We provide two challenging task types, three difficulty levels, five simulated environments and a new evaluation measure for evaluating 3D cuboid object maps.
[arXiv]
[website]
Being able to explore an environment and understand the location and type of all objects therein is important for indoor robotic platforms that must interact closely with humans. However, it is difficult to evaluate progress in this area due to a lack of standardized testing which is limited due to the need for active robot agency and perfect object ground-truth. To help provide a standard for testing scene understanding systems, we present a new robot vision scene understanding challenge using simulation to enable repeatable experiments with active robot agency. We provide two challenging task types, three difficulty levels, five simulated environments and a new evaluation measure for evaluating 3D cuboid object maps.
[arXiv]
[website]
-
Benchbot: Evaluating robotics research in photorealistic 3d simulation and on real robots arXiv preprint arXiv:2008.00635, 2020.
 We introduce BenchBot, a novel software suite for benchmarking the performance of robotics research across both photorealistic 3D simulations and real robot platforms. BenchBot provides a simple interface to the sensorimotor capabilities of a robot when solving robotics research problems; an interface that is consistent regardless of whether the target platform is simulated or a real robot. In this paper we outline the BenchBot system architecture, and explore the parallels between its user-centric design and an ideal research development process devoid of tangential robot engineering challenges.
[arXiv]
[website]
We introduce BenchBot, a novel software suite for benchmarking the performance of robotics research across both photorealistic 3D simulations and real robot platforms. BenchBot provides a simple interface to the sensorimotor capabilities of a robot when solving robotics research problems; an interface that is consistent regardless of whether the target platform is simulated or a real robot. In this paper we outline the BenchBot system architecture, and explore the parallels between its user-centric design and an ideal research development process devoid of tangential robot engineering challenges.
[arXiv]
[website]
-
Performance Monitoring of Object Detection During Deployment arXiv preprint arXiv:2009.08650, 2020.
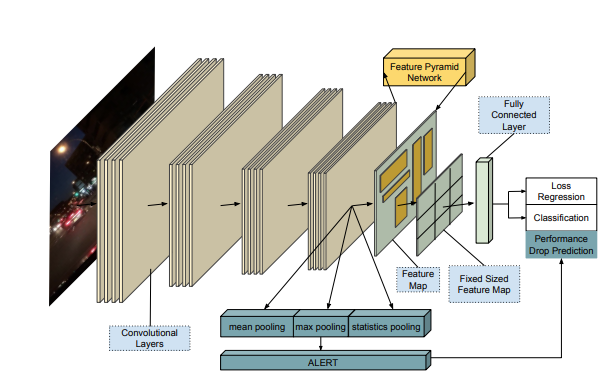 Performance monitoring of object detection is crucial for safety-critical applications such as autonomous vehicles that operate under varying and complex environmental conditions. Currently, object detectors are evaluated using summary metrics based on a single dataset that is assumed to be representative of all future deployment conditions. In practice, this assumption does not hold, and the performance fluctuates as a function of the deployment conditions. To address this issue, we propose an introspection approach to performance monitoring during deployment without the need for ground truth data. We do so by predicting when the per-frame mean average precision drops below a critical threshold using the detector’s internal features.
[arXiv]
Performance monitoring of object detection is crucial for safety-critical applications such as autonomous vehicles that operate under varying and complex environmental conditions. Currently, object detectors are evaluated using summary metrics based on a single dataset that is assumed to be representative of all future deployment conditions. In practice, this assumption does not hold, and the performance fluctuates as a function of the deployment conditions. To address this issue, we propose an introspection approach to performance monitoring during deployment without the need for ground truth data. We do so by predicting when the per-frame mean average precision drops below a critical threshold using the detector’s internal features.
[arXiv]
-
What can robotics research learn from computer vision research? arXiv preprint arXiv:2001.02366, 2020.
 The computer vision and robotics research communities are each strong. However progress in computer vision has become turbo-charged in recent years due to big data, GPU computing, novel learning algorithms and a very effective research methodology. By comparison, progress in robotics seems slower. It is true that robotics came later to exploring the potential of learning – the advantages over the well-established body of knowledge in dynamics, kinematics, planning and control is still being debated, although reinforcement learning seems to offer real potential. However, the rapid development of computer vision compared to robotics cannot be only attributed to the former’s adoption of deep learning. In this paper, we argue that the gains in computer vision are due to research methodology – evaluation under strict constraints versus experiments; bold numbers versus videos.
[arXiv]
The computer vision and robotics research communities are each strong. However progress in computer vision has become turbo-charged in recent years due to big data, GPU computing, novel learning algorithms and a very effective research methodology. By comparison, progress in robotics seems slower. It is true that robotics came later to exploring the potential of learning – the advantages over the well-established body of knowledge in dynamics, kinematics, planning and control is still being debated, although reinforcement learning seems to offer real potential. However, the rapid development of computer vision compared to robotics cannot be only attributed to the former’s adoption of deep learning. In this paper, we argue that the gains in computer vision are due to research methodology – evaluation under strict constraints versus experiments; bold numbers versus videos.
[arXiv]
2019
Journal Articles
-
A Probabilistic Challenge for Object Detection Nature Machine Intelligence, 2019.
 To safely operate in the real world, robots need to evaluate how confident they are about what they see.
A new competition challenges computer vision algorithms to not just detect and localize objects, but also report how certain they are.
To this end, we introduce Probabilistic Object Detection, the task of detecting objects in images and accurately quantifying the spatial and semantic uncertainties of the detections.
To safely operate in the real world, robots need to evaluate how confident they are about what they see.
A new competition challenges computer vision algorithms to not just detect and localize objects, but also report how certain they are.
To this end, we introduce Probabilistic Object Detection, the task of detecting objects in images and accurately quantifying the spatial and semantic uncertainties of the detections.
Conference Publications
-
Evaluating Merging Strategies for Sampling-based Uncertainty Techniques in Object Detection In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2019.
 There has been a recent emergence of sampling-based techniques for estimating epistemic uncertainty in deep neural networks. While these methods can be applied to classification or semantic segmentation tasks by simply averaging samples, this is not the case for object detection, where detection sample bounding boxes must be accurately associated and merged. A weak merging strategy can significantly degrade the performance of the detector and yield an unreliable uncertainty measure. This paper provides the first in-depth investigation of the effect of different association and merging strategies. We compare different combinations of three spatial and two semantic affinity measures with four clustering methods for MC Dropout with a Single Shot Multi-Box Detector. Our results show that the correct choice of affinity-clustering combinations can greatly improve the effectiveness of the classification and spatial uncertainty estimation and the resulting object detection performance. We base our evaluation on a new mix of datasets that emulate near open-set conditions (semantically similar unknown classes), distant open-set conditions (semantically dissimilar unknown classes) and the common closed-set conditions (only known classes).
[arXiv]
There has been a recent emergence of sampling-based techniques for estimating epistemic uncertainty in deep neural networks. While these methods can be applied to classification or semantic segmentation tasks by simply averaging samples, this is not the case for object detection, where detection sample bounding boxes must be accurately associated and merged. A weak merging strategy can significantly degrade the performance of the detector and yield an unreliable uncertainty measure. This paper provides the first in-depth investigation of the effect of different association and merging strategies. We compare different combinations of three spatial and two semantic affinity measures with four clustering methods for MC Dropout with a Single Shot Multi-Box Detector. Our results show that the correct choice of affinity-clustering combinations can greatly improve the effectiveness of the classification and spatial uncertainty estimation and the resulting object detection performance. We base our evaluation on a new mix of datasets that emulate near open-set conditions (semantically similar unknown classes), distant open-set conditions (semantically dissimilar unknown classes) and the common closed-set conditions (only known classes).
[arXiv]
-
Sim-to-Real Transfer of Robot Learning with Variable Length Inputs In Australasian Conf. for Robotics and Automation (ACRA), 2019.
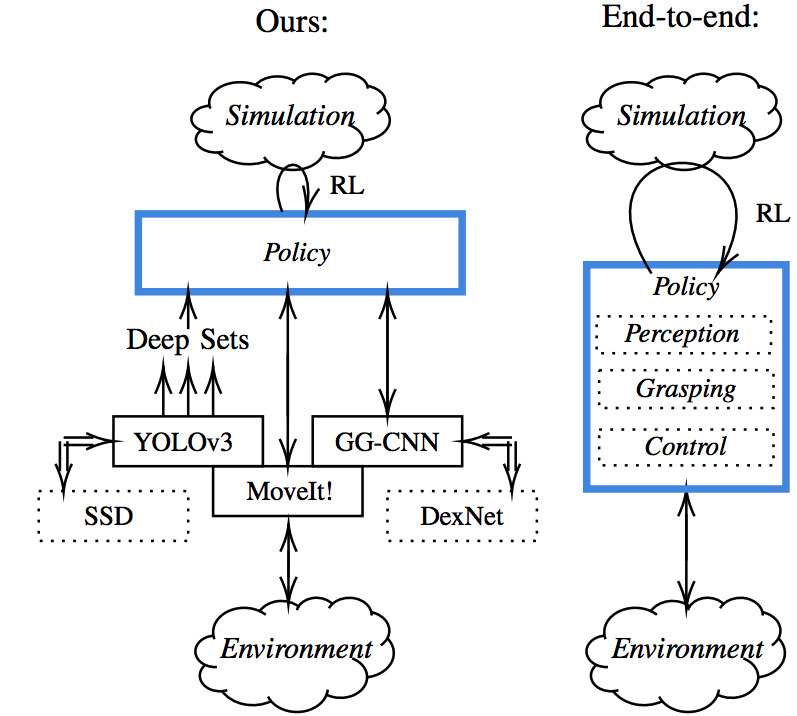 Current end-to-end deep Reinforcement Learning (RL) approaches require jointly learning perception, decision-making and low-level control from very sparse reward signals and high-dimensional inputs, with little capability of incorporating prior knowledge. In this work, we propose a framework that combines deep sets encoding, which allows for variable-length abstract representations, with modular RL that utilizes these representations, decoupling high-level decision making from low-level control. We successfully demonstrate our approach on the robot manipulation task of object sorting, showing that this method can learn effective policies within mere minutes of highly simplified simulation. The learned policies can be directly deployed on a robot without further training, and generalize to variations of the task unseen during training.
[arXiv]
Current end-to-end deep Reinforcement Learning (RL) approaches require jointly learning perception, decision-making and low-level control from very sparse reward signals and high-dimensional inputs, with little capability of incorporating prior knowledge. In this work, we propose a framework that combines deep sets encoding, which allows for variable-length abstract representations, with modular RL that utilizes these representations, decoupling high-level decision making from low-level control. We successfully demonstrate our approach on the robot manipulation task of object sorting, showing that this method can learn effective policies within mere minutes of highly simplified simulation. The learned policies can be directly deployed on a robot without further training, and generalize to variations of the task unseen during training.
[arXiv]
-
Airborne Particle Classification in LiDAR Point Clouds Using Deep Learning In Proceedings of the Conference on Field and Service Robotics (FSR), 2019.
 In this work, we propose and compare two deep learning approaches to classify airborne particles in LiDAR data. The first is based on voxel-wise classification, while the second is based on point-wise classification. We also study the impact of different combinations of input features extracted from LiDAR data, including the use of multi-echo returns as a classification feature. We evaluate the performance of the proposed methods on a realistic dataset with the presence of fog and dust particles in outdoor scenes. We achieve an F1 score of 94% for the classification of airborne particles in LiDAR point clouds, thereby significantly outperforming the state-of-the-art.
In this work, we propose and compare two deep learning approaches to classify airborne particles in LiDAR data. The first is based on voxel-wise classification, while the second is based on point-wise classification. We also study the impact of different combinations of input features extracted from LiDAR data, including the use of multi-echo returns as a classification feature. We evaluate the performance of the proposed methods on a realistic dataset with the presence of fog and dust particles in outdoor scenes. We achieve an F1 score of 94% for the classification of airborne particles in LiDAR point clouds, thereby significantly outperforming the state-of-the-art.
-
Did You Miss the Sign? A False Negative Alarm System for Traffic Sign Detectors In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2019.
 In this paper, we propose an approach to identify traffic signs that have been mistakenly discarded by the object detector. The proposed method raises an alarm when it discovers a failure by the object detector to detect a traffic sign. This approach can be useful to evaluate the performance of the detector during the deployment phase. We trained a single shot multi-box object detector to detect traffic signs and used its internal features to train a separate false negative detector (FND). During deployment, FND decides whether the traffic sign detector has missed a sign or not.
[arXiv]
In this paper, we propose an approach to identify traffic signs that have been mistakenly discarded by the object detector. The proposed method raises an alarm when it discovers a failure by the object detector to detect a traffic sign. This approach can be useful to evaluate the performance of the detector during the deployment phase. We trained a single shot multi-box object detector to detect traffic signs and used its internal features to train a separate false negative detector (FND). During deployment, FND decides whether the traffic sign detector has missed a sign or not.
[arXiv]
-
Look No Deeper: Recognizing Places from Opposing Viewpoints under Varying Scene Appearance using Single-View Depth Estimation In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2019.
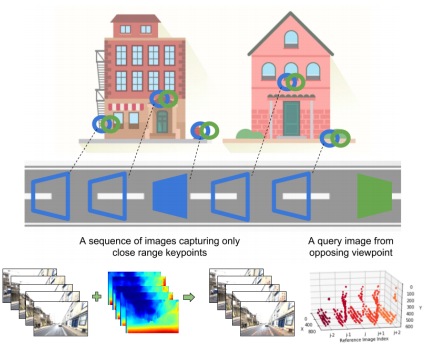 We present a new depth-and temporal-aware visual place recognition system that solves the opposing viewpoint, extreme appearance-change visual place recognition problem. Our system performs sequence-to-single matching by extracting depth-filtered keypoints using a state-of-the-art depth estimation pipeline, constructing a keypoint sequence over multiple frames from the reference dataset, and comparing those keypoints to those in a single query image. We evaluate the system on a challenging benchmark dataset and show that it consistently outperforms state-of-the-art techniques. We also develop a range of diagnostic simulation experiments that characterize the contribution of depth-filtered keypoint sequences with respect to key domain parameters including degree of appearance change and camera motion.
[arXiv]
We present a new depth-and temporal-aware visual place recognition system that solves the opposing viewpoint, extreme appearance-change visual place recognition problem. Our system performs sequence-to-single matching by extracting depth-filtered keypoints using a state-of-the-art depth estimation pipeline, constructing a keypoint sequence over multiple frames from the reference dataset, and comparing those keypoints to those in a single query image. We evaluate the system on a challenging benchmark dataset and show that it consistently outperforms state-of-the-art techniques. We also develop a range of diagnostic simulation experiments that characterize the contribution of depth-filtered keypoint sequences with respect to key domain parameters including degree of appearance change and camera motion.
[arXiv]
Workshop Publications
-
Benchmarking Sampling-based Probabilistic Object Detectors In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2019.
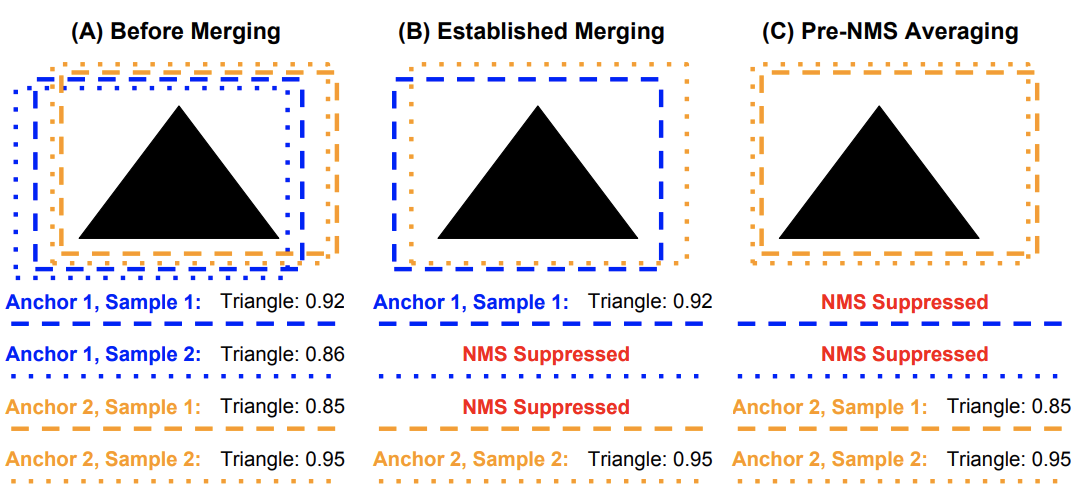 This paper provides the first benchmark for sampling-based probabilistic object detectors. A probabilistic object
detector expresses uncertainty for all detections that reliably indicates object localisation and classification performance. We compare performance for two sampling-based
uncertainty techniques, namely Monte Carlo Dropout and Deep Ensembles, when implemented into one-stage and
two-stage object detectors, Single Shot MultiBox Detector and Faster R-CNN.
This paper provides the first benchmark for sampling-based probabilistic object detectors. A probabilistic object
detector expresses uncertainty for all detections that reliably indicates object localisation and classification performance. We compare performance for two sampling-based
uncertainty techniques, namely Monte Carlo Dropout and Deep Ensembles, when implemented into one-stage and
two-stage object detectors, Single Shot MultiBox Detector and Faster R-CNN.
arXiv Preprints
-
Where are the Keys? – Learning Object-Centric Navigation Policies on Semantic Maps with Graph Convolutional Networks arXiv preprint arXiv:1909.07376, 2019.
 Emerging object-based SLAM algorithms can build a graph representation of an environment comprising nodes for robot poses and object landmarks. However, while this map will contain static objects such as furniture or appliances, many moveable objects (e.g. the car keys, the glasses, or a magazine), are not suitable as landmarks and will not be part of the map due to their non-static nature. We show that Graph Convolutional Networks can learn navigation policies to find such unmapped objects by learning to exploit the hidden probabilistic model that governs where these objects appear in the environment. The learned policies can generalise to object classes unseen during training by using word vectors that express semantic similarity as representations for object nodes in the graph. Furthermore, we show that the policies generalise to unseen environments with only minimal loss of performance. We demonstrate that pre-training the policy network with a proxy task can significantly speed up learning, improving sample efficiency.
[arXiv]
Emerging object-based SLAM algorithms can build a graph representation of an environment comprising nodes for robot poses and object landmarks. However, while this map will contain static objects such as furniture or appliances, many moveable objects (e.g. the car keys, the glasses, or a magazine), are not suitable as landmarks and will not be part of the map due to their non-static nature. We show that Graph Convolutional Networks can learn navigation policies to find such unmapped objects by learning to exploit the hidden probabilistic model that governs where these objects appear in the environment. The learned policies can generalise to object classes unseen during training by using word vectors that express semantic similarity as representations for object nodes in the graph. Furthermore, we show that the policies generalise to unseen environments with only minimal loss of performance. We demonstrate that pre-training the policy network with a proxy task can significantly speed up learning, improving sample efficiency.
[arXiv]
2018
Journal Articles
-
QuadricSLAM: Constrained Dual Quadrics from Object Detections as Landmarks in Object-oriented SLAM IEEE Robotics and Automation Letters (RA-L), 2018.
 In this paper, we use 2D object detections from multiple views to simultaneously estimate a 3D quadric surface for each object and localize the camera position. We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D object detections can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for object detectors that addresses the challenge of partially visible objects, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
In this paper, we use 2D object detections from multiple views to simultaneously estimate a 3D quadric surface for each object and localize the camera position. We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D object detections can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for object detectors that addresses the challenge of partially visible objects, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
-
The Limits and Potentials of Deep Learning for Robotics The International Journal of Robotics Research, 2018.
 The application of deep learning in robotics leads
to very specific problems and research questions that are
typically not addressed by the computer vision and machine
learning communities. In this paper we discuss a number
of robotics-specific learning, reasoning, and embodiment challenges
for deep learning. We explain the need for better evaluation
metrics, highlight the importance and unique challenges for
deep robotic learning in simulation, and explore the spectrum
between purely data-driven and model-driven approaches. We
hope this paper provides a motivating overview of important
research directions to overcome the current limitations, and
help fulfill the promising potentials of deep learning in robotics.
[arXiv]
The application of deep learning in robotics leads
to very specific problems and research questions that are
typically not addressed by the computer vision and machine
learning communities. In this paper we discuss a number
of robotics-specific learning, reasoning, and embodiment challenges
for deep learning. We explain the need for better evaluation
metrics, highlight the importance and unique challenges for
deep robotic learning in simulation, and explore the spectrum
between purely data-driven and model-driven approaches. We
hope this paper provides a motivating overview of important
research directions to overcome the current limitations, and
help fulfill the promising potentials of deep learning in robotics.
[arXiv]
Special Issues
-
Special Issue on Deep Learning in Robotics The International Journal of Robotics Research (IJRR), 2018.
Conference Publications
-
Structure Aware SLAM using Quadrics and Planes In Proceedings of Asian Conference on Computer Vision (ACCV), 2018. [arXiv]
-
Lidar-based Detection of Airborne Particles for Robust Robot Perception In Proceedings of Australasian Conference on Robotics and Automation (ACRA), 2018.
-
Learning Deployable Navigation Policies at Kilometer Scale from a Single Traversal In Proc. of Conference on Robot Learning (CoRL), 2018.
 We present an approach for efficiently learning goal-directed navigation policies on a mobile robot, from only a single coverage traversal of recorded data. The navigation agent learns an effective policy over a diverse action space in a large heterogeneous environment consisting of more than 2km of travel, through buildings and outdoor regions that collectively exhibit large variations in visual appearance, self-similarity, and connectivity. We compare pretrained visual encoders that enable precomputation of visual embeddings to achieve a throughput of tens of thousands of transitions per second at training time on a commodity desktop computer, allowing agents to learn from millions of trajectories of experience in a matter of hours. We propose multiple forms of computationally efficient stochastic augmentation to enable the learned policy to generalise beyond these precomputed embeddings, and demonstrate successful deployment of the learned policy on the real robot without fine tuning, despite environmental appearance differences at test time.
[arXiv]
[website]
We present an approach for efficiently learning goal-directed navigation policies on a mobile robot, from only a single coverage traversal of recorded data. The navigation agent learns an effective policy over a diverse action space in a large heterogeneous environment consisting of more than 2km of travel, through buildings and outdoor regions that collectively exhibit large variations in visual appearance, self-similarity, and connectivity. We compare pretrained visual encoders that enable precomputation of visual embeddings to achieve a throughput of tens of thousands of transitions per second at training time on a commodity desktop computer, allowing agents to learn from millions of trajectories of experience in a matter of hours. We propose multiple forms of computationally efficient stochastic augmentation to enable the learned policy to generalise beyond these precomputed embeddings, and demonstrate successful deployment of the learned policy on the real robot without fine tuning, despite environmental appearance differences at test time.
[arXiv]
[website]
-
LoST? Appearance-Invariant Place Recognition for Opposite Viewpoints using Visual Semantics In Proc. of Robotics: Science and Systems (RSS), 2018.
In this paper we develop a suite of novel semantic- and appearance-based techniques to enable for the first time high performance place recognition in the challenging scenario of recognizing places when returning from the opposite direction. We first propose a novel Local Semantic Tensor (LoST) descriptor of images using the convolutional feature maps from a state-of-the-art dense semantic segmentation network. Then, to verify the spatial semantic arrangement of the top matching candidates, we develop a novel approach for mining semantically-salient keypoint correspondences.
-
Dropout Sampling for Robust Object Detection in Open-Set Conditions In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2018.
 Dropout Variational Inference, or Dropout Sampling, has been recently proposed as an
approximation technique for Bayesian Deep Learning and evaluated for image classification
and regression tasks. This paper investigates the utility of Dropout Sampling for object
detection for the first time. We demonstrate how label uncertainty can be extracted from a
state-of-the-art object detection system via Dropout Sampling. We show that this uncertainty
can be utilized to increase object detection performance under the open-set conditions that
are typically encountered in robotic vision. We evaluate this approach on a large synthetic
dataset with 30,000 images, and a real-world dataset captured by a mobile robot in a
versatile campus environment.
Dropout Variational Inference, or Dropout Sampling, has been recently proposed as an
approximation technique for Bayesian Deep Learning and evaluated for image classification
and regression tasks. This paper investigates the utility of Dropout Sampling for object
detection for the first time. We demonstrate how label uncertainty can be extracted from a
state-of-the-art object detection system via Dropout Sampling. We show that this uncertainty
can be utilized to increase object detection performance under the open-set conditions that
are typically encountered in robotic vision. We evaluate this approach on a large synthetic
dataset with 30,000 images, and a real-world dataset captured by a mobile robot in a
versatile campus environment.
-
Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments In Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
 To enable and encourage the application of vision and
language methods to the problem of interpreting visually grounded
navigation instructions, we present the Matterport3D
Simulator – a large-scale reinforcement learning
environment based on real imagery. Using this simulator,
which can in future support a range of embodied vision
and language tasks, we provide the first benchmark dataset
for visually-grounded natural language navigation in real
buildings – the Room-to-Room (R2R) dataset.
To enable and encourage the application of vision and
language methods to the problem of interpreting visually grounded
navigation instructions, we present the Matterport3D
Simulator – a large-scale reinforcement learning
environment based on real imagery. Using this simulator,
which can in future support a range of embodied vision
and language tasks, we provide the first benchmark dataset
for visually-grounded natural language navigation in real
buildings – the Room-to-Room (R2R) dataset.
-
Don’t Look Back: Robustifying Place Categorization for Viewpoint- and Condition-Invariant Place Recognition In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2018.
 In this work, we develop a novel methodology for using the semantics-aware
higher-order layers of deep neural networks for recognizing
specific places from within a reference database. To further
improve the robustness to appearance change, we develop a
descriptor normalization scheme that builds on the success of
normalization schemes for pure appearance-based techniques.
In this work, we develop a novel methodology for using the semantics-aware
higher-order layers of deep neural networks for recognizing
specific places from within a reference database. To further
improve the robustness to appearance change, we develop a
descriptor normalization scheme that builds on the success of
normalization schemes for pure appearance-based techniques.
-
SceneCut: Joint Geometric and Object Segmentation for Indoor Scenes In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2018.
 This paper presents SceneCut, a novel approach to jointly discover previously unseen
objects and non-object surfaces using a single RGB-D image. SceneCut’s joint reasoning
over scene semantics and geometry allows a robot to detect and segment object instances
in complex scenes where modern deep learning-based methods either fail to separate
object instances, or fail to detect objects that were not seen during training. SceneCut
automatically decomposes a scene into meaningful regions which either represent objects
or scene surfaces. The decomposition is qualified by an unified energy function over
objectness and geometric fitting. We show how this energy function can be optimized
efficiently by utilizing hierarchical segmentation trees.
This paper presents SceneCut, a novel approach to jointly discover previously unseen
objects and non-object surfaces using a single RGB-D image. SceneCut’s joint reasoning
over scene semantics and geometry allows a robot to detect and segment object instances
in complex scenes where modern deep learning-based methods either fail to separate
object instances, or fail to detect objects that were not seen during training. SceneCut
automatically decomposes a scene into meaningful regions which either represent objects
or scene surfaces. The decomposition is qualified by an unified energy function over
objectness and geometric fitting. We show how this energy function can be optimized
efficiently by utilizing hierarchical segmentation trees.
Workshop Publications
-
QuadricSLAM: Constrained Dual Quadrics from Object Detections as Landmarks in Semantic SLAM In Workshop on Representing a Complex World, International Conference on Robotics and Automation (ICRA), 2018. Best Workshop Paper Award
 We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D bounding boxes (such as those typically obtained from visual object detection systems) can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for deep-learned object detectors that addresses the challenge of partial object detections often encountered in robotics applications, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D bounding boxes (such as those typically obtained from visual object detection systems) can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for deep-learned object detectors that addresses the challenge of partial object detections often encountered in robotics applications, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
arXiv Preprints
-
An Orientation Factor for Object-Oriented SLAM arXiv preprint, 2018.
 Current approaches to object-oriented SLAM lack the ability to incorporate prior knowledge of the scene geometry, such as the expected global orientation of objects. We overcome this limitation by proposing a geometric factor that constrains the global orientation of objects in the map, depending on the objects’ semantics. This new geometric factor is a first example of how semantics can inform and improve geometry in object-oriented SLAM. We implement the geometric factor for the recently proposed QuadricSLAM that represents landmarks as dual quadrics. The factor probabilistically models the quadrics’ major axes to be either perpendicular to or aligned with the direction of gravity, depending on their semantic class. Our experiments on simulated and real-world datasets show that using the proposed factors to incorporate prior knowledge improves both the trajectory and landmark quality.
[arXiv]
[website]
Current approaches to object-oriented SLAM lack the ability to incorporate prior knowledge of the scene geometry, such as the expected global orientation of objects. We overcome this limitation by proposing a geometric factor that constrains the global orientation of objects in the map, depending on the objects’ semantics. This new geometric factor is a first example of how semantics can inform and improve geometry in object-oriented SLAM. We implement the geometric factor for the recently proposed QuadricSLAM that represents landmarks as dual quadrics. The factor probabilistically models the quadrics’ major axes to be either perpendicular to or aligned with the direction of gravity, depending on their semantic class. Our experiments on simulated and real-world datasets show that using the proposed factors to incorporate prior knowledge improves both the trajectory and landmark quality.
[arXiv]
[website]
2017
Journal Articles
-
Multi-Modal Trip Hazard Affordance Detection On Construction Sites IEEE Robotics and Automation Letters (RA-L), 2017.
 Trip hazards are a significant contributor to accidents on construction and manufacturing sites. We conduct a comprehensive investigation into the performance characteristics of 11 different colors and depth fusion approaches, including four fusion and one nonfusion approach, using color and two types of depth images. Trained and tested on more than 600 labeled trip hazards over four floors and 2000 m2 in an active construction site, this approach was able to differentiate between identical objects in different physical configurations. Outperforming a color-only detector, our multimodal trip detector fuses color and depth information to achieve a 4% absolute improvement in F1-score. These investigative results and the extensive publicly available dataset move us one step closer to assistive or fully automated safety inspection systems on construction sites.
Trip hazards are a significant contributor to accidents on construction and manufacturing sites. We conduct a comprehensive investigation into the performance characteristics of 11 different colors and depth fusion approaches, including four fusion and one nonfusion approach, using color and two types of depth images. Trained and tested on more than 600 labeled trip hazards over four floors and 2000 m2 in an active construction site, this approach was able to differentiate between identical objects in different physical configurations. Outperforming a color-only detector, our multimodal trip detector fuses color and depth information to achieve a 4% absolute improvement in F1-score. These investigative results and the extensive publicly available dataset move us one step closer to assistive or fully automated safety inspection systems on construction sites.
Conference Publications
-
Meaningful Maps With Object-Oriented Semantic Mapping In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2017.
 For intelligent robots to interact in meaningful ways with their environment, they must understand both the geometric and semantic properties of the scene surrounding them. The majority of research to date has addressed these mapping challenges separately, focusing on either geometric or semantic mapping. In this paper we address the problem of building environmental maps that include both semantically meaningful, object-level entities and point- or mesh-based geometrical representations. We simultaneously build geometric point cloud models of previously unseen instances of known object classes and create a map that contains these object models as central entities. Our system leverages sparse, feature-based RGB-D SLAM, image-based deep-learning object detection and 3D unsupervised segmentation.
For intelligent robots to interact in meaningful ways with their environment, they must understand both the geometric and semantic properties of the scene surrounding them. The majority of research to date has addressed these mapping challenges separately, focusing on either geometric or semantic mapping. In this paper we address the problem of building environmental maps that include both semantically meaningful, object-level entities and point- or mesh-based geometrical representations. We simultaneously build geometric point cloud models of previously unseen instances of known object classes and create a map that contains these object models as central entities. Our system leverages sparse, feature-based RGB-D SLAM, image-based deep-learning object detection and 3D unsupervised segmentation.
-
The ACRV Picking Benchmark: A Robotic Shelf Picking Benchmark to Foster Reproducible Research In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2017.
 Robotic challenges like the Amazon Picking Challenge (APC) or the DARPA Challenges are an established and important way to drive scientific progress. They make research comparable on a well-defined benchmark with equal test conditions for all participants. However, such challenge events occur only occasionally, are limited to a small number of contestants, and the test conditions are very difficult to replicate after the main event. We present a new physical benchmark challenge for robotic picking: the ACRV Picking Benchmark. Designed to be reproducible, it consists of a set of 42 common objects, a widely available shelf, and exact guidelines for object arrangement using stencils. A well-defined evaluation protocol enables the comparison of complete robotic systems - including perception and manipulation - instead of sub-systems only. Our paper also describes and reports results achieved by an open baseline system based on a Baxter robot.
Robotic challenges like the Amazon Picking Challenge (APC) or the DARPA Challenges are an established and important way to drive scientific progress. They make research comparable on a well-defined benchmark with equal test conditions for all participants. However, such challenge events occur only occasionally, are limited to a small number of contestants, and the test conditions are very difficult to replicate after the main event. We present a new physical benchmark challenge for robotic picking: the ACRV Picking Benchmark. Designed to be reproducible, it consists of a set of 42 common objects, a widely available shelf, and exact guidelines for object arrangement using stencils. A well-defined evaluation protocol enables the comparison of complete robotic systems - including perception and manipulation - instead of sub-systems only. Our paper also describes and reports results achieved by an open baseline system based on a Baxter robot.
-
Deep Learning Features at Scale for Visual Place Recognition In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2017.
 In this paper, we train, at large scale, two CNN architectures for the specific place recognition task and employ a multi-scale feature encoding method to generate condition- and viewpoint-invariant features. To enable this training to occur, we have developed a massive Specific PlacEs Dataset (SPED) with hundreds of examples of place appearance change at thousands of different places, as opposed to the semantic place type datasets currently available. This new dataset enables us to set up a training regime that interprets place recognition as a classification problem. We comprehensively evaluate our trained networks on several challenging benchmark place recognition datasets and demonstrate that they achieve an average 10% increase in performance over other place recognition algorithms and pre-trained CNNs.
In this paper, we train, at large scale, two CNN architectures for the specific place recognition task and employ a multi-scale feature encoding method to generate condition- and viewpoint-invariant features. To enable this training to occur, we have developed a massive Specific PlacEs Dataset (SPED) with hundreds of examples of place appearance change at thousands of different places, as opposed to the semantic place type datasets currently available. This new dataset enables us to set up a training regime that interprets place recognition as a classification problem. We comprehensively evaluate our trained networks on several challenging benchmark place recognition datasets and demonstrate that they achieve an average 10% increase in performance over other place recognition algorithms and pre-trained CNNs.
-
Auxiliary Tasks to Improve Trip Hazard Affordance Detection In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2017.
 We propose to train a CNN performing pixel-wise trip detection with three auxiliary tasks to help the CNN better infer scene geometric properties of trip hazards. Of the three approaches investigated pixel-wise ground plane estimation, pixel depth estimation and pixel height above ground plane estimation, the first approach allowed the trip detector to achieve a 11.1% increase in Trip IOU over earlier work. These new approaches make it plausible to deploy a robotic platform to perform trip hazard detection, and so potentially reduce the number of injuries on construction sites.
We propose to train a CNN performing pixel-wise trip detection with three auxiliary tasks to help the CNN better infer scene geometric properties of trip hazards. Of the three approaches investigated pixel-wise ground plane estimation, pixel depth estimation and pixel height above ground plane estimation, the first approach allowed the trip detector to achieve a 11.1% increase in Trip IOU over earlier work. These new approaches make it plausible to deploy a robotic platform to perform trip hazard detection, and so potentially reduce the number of injuries on construction sites.
Workshop Publications
-
Dropout Variational Inference Improves Object Detection in Open-Set Conditions In Proc. of NIPS Workshop on Bayesian Deep Learning, 2017.
 One of the biggest current challenges of visual object detection is reliable operation in open-set
conditions. One way to handle the open-set problem is to utilize the uncertainty of the model to reject predictions
with low probability. Bayesian Neural Networks (BNNs), with variational inference commonly
used as an approximation, is an established approach to estimate model uncertainty. Here we extend the concept of Dropout sampling to object detection for the first time. We evaluate
Bayesian object detection on a large synthetic and a real-world dataset and show how the estimated
label uncertainty can be utilized to increase object detection performance under open-set conditions.
One of the biggest current challenges of visual object detection is reliable operation in open-set
conditions. One way to handle the open-set problem is to utilize the uncertainty of the model to reject predictions
with low probability. Bayesian Neural Networks (BNNs), with variational inference commonly
used as an approximation, is an established approach to estimate model uncertainty. Here we extend the concept of Dropout sampling to object detection for the first time. We evaluate
Bayesian object detection on a large synthetic and a real-world dataset and show how the estimated
label uncertainty can be utilized to increase object detection performance under open-set conditions.
-
Episode-Based Active Learning with Bayesian Neural Networks In Workshop on Deep Learning for Robotic Vision, Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
 We investigate different strategies for active learning
with Bayesian deep neural networks. We focus our analysis
on scenarios where new, unlabeled data is obtained episodically,
such as commonly encountered in mobile robotics
applications. An evaluation of different strategies for acquisition,
updating, and final training on the CIFAR-10 dataset
shows that incremental network updates with final training
on the accumulated acquisition set are essential for best
performance, while limiting the amount of required human
labeling labor.
We investigate different strategies for active learning
with Bayesian deep neural networks. We focus our analysis
on scenarios where new, unlabeled data is obtained episodically,
such as commonly encountered in mobile robotics
applications. An evaluation of different strategies for acquisition,
updating, and final training on the CIFAR-10 dataset
shows that incremental network updates with final training
on the accumulated acquisition set are essential for best
performance, while limiting the amount of required human
labeling labor.
-
One-Shot Reinforcement Learning for Robot Navigation with Interactive Replay In Proc. of NIPS Workshop on Acting and Interacting in the Real World: Challenges in Robot Learning, 2017.
 Recently, model-free reinforcement learning algorithms have been shown to solve challenging problems by learning from extensive interaction with the environment. A significant issue with transferring this success to the robotics domain is that interaction with the real world is costly, but training on limited experience is prone to overfitting. We present a method for learning to navigate, to a fixed goal and in a known environment, on a mobile robot. The robot leverages an interactive world model built from a single traversal of the environment, a pre-trained visual feature encoder, and stochastic environmental augmentation, to demonstrate successful zero-shot transfer under real-world environmental variations without fine-tuning.
Recently, model-free reinforcement learning algorithms have been shown to solve challenging problems by learning from extensive interaction with the environment. A significant issue with transferring this success to the robotics domain is that interaction with the real world is costly, but training on limited experience is prone to overfitting. We present a method for learning to navigate, to a fixed goal and in a known environment, on a mobile robot. The robot leverages an interactive world model built from a single traversal of the environment, a pre-trained visual feature encoder, and stochastic environmental augmentation, to demonstrate successful zero-shot transfer under real-world environmental variations without fine-tuning.
2016
Conference Publications
-
A Robustness Analysis of Deep Q Networks In Proc. of Australasian Conference on Robotics and Automation (ACRA), 2016.
 In this paper, we present an analysis of the robustness of Deep Q Networks to various types of perceptual noise (changing brightness, Gaussian blur, salt and pepper, distractors). We present a benchmark example that involves playing the game Breakout though a webcam and screen environment, like humans do. We present a simple training approach to improve the performance maintained when transferring a DQN agent trained in simulation to the real world. We also evaluate DQN agents trained under a variety of simulation environments to report for the first time how DQNs cope with perceptual noise, common to real world robotic applications.
In this paper, we present an analysis of the robustness of Deep Q Networks to various types of perceptual noise (changing brightness, Gaussian blur, salt and pepper, distractors). We present a benchmark example that involves playing the game Breakout though a webcam and screen environment, like humans do. We present a simple training approach to improve the performance maintained when transferring a DQN agent trained in simulation to the real world. We also evaluate DQN agents trained under a variety of simulation environments to report for the first time how DQNs cope with perceptual noise, common to real world robotic applications.
-
High-Fidelity Simulation for Evaluating Robotic Vision Performance In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2016.
 For machine learning applications a critical bottleneck is the limited amount of real world image data that can be captured and labelled for both training and testing purposes. In this paper we investigate the use of a photo-realistic simulation tool to address these challenges, in three specific domains: robust place recognition, visual SLAM and object recognition. For the first two problems we generate images from a complex 3D environment with systematically varying camera paths, camera viewpoints and lighting conditions. For the first time we are able to systematically characterise the performance of these algorithms as paths and lighting conditions change. In particular, we are able to systematically generate varying camera viewpoint datasets that would be difficult or impossible to generate in the real world. We also compare algorithm results for a camera in a real environment and a simulated camera in a simulation model of that real environment. Finally, for the object recognition domain, we generate labelled image data and characterise the viewpoint dependency of a current convolution neural network in performing object recognition. Together these results provide a multi-domain demonstration of the beneficial properties of using simulation to characterise and analyse a wide range of robotic vision algorithms.
For machine learning applications a critical bottleneck is the limited amount of real world image data that can be captured and labelled for both training and testing purposes. In this paper we investigate the use of a photo-realistic simulation tool to address these challenges, in three specific domains: robust place recognition, visual SLAM and object recognition. For the first two problems we generate images from a complex 3D environment with systematically varying camera paths, camera viewpoints and lighting conditions. For the first time we are able to systematically characterise the performance of these algorithms as paths and lighting conditions change. In particular, we are able to systematically generate varying camera viewpoint datasets that would be difficult or impossible to generate in the real world. We also compare algorithm results for a camera in a real environment and a simulated camera in a simulation model of that real environment. Finally, for the object recognition domain, we generate labelled image data and characterise the viewpoint dependency of a current convolution neural network in performing object recognition. Together these results provide a multi-domain demonstration of the beneficial properties of using simulation to characterise and analyse a wide range of robotic vision algorithms.
-
LunaRoo: Designing a Hopping Lunar Science Payload. In Proc. of IEEE Aerospace Conference, 2016.
 We describe a hopping science payload solution designed to exploit the Moon’s lower gravity to leap up to 20m above the surface. The entire solar-powered robot is compact enough to fit within a 10cm cube, whilst providing unique observation and mission capabilities by creating imagery during the hop. The LunaRoo concept is a proposed payload to fly onboard a Google Lunar XPrize entry. Its compact form is specifically designed for lunar exploration and science mission within the constraints given by PTScientists. The core features of LunaRoo are its method of locomotion - hopping like a kangaroo - and its imaging system capable of unique over-the-horizon perception. The payload will serve as a proof of concept, highlighting the benefits of alternative mobility solutions, in particular enabling observation and exploration of terrain not traversable by wheeled robots. in addition providing data for beyond line-of-sight planning and communications for surface assets, extending overall mission capabilities.
We describe a hopping science payload solution designed to exploit the Moon’s lower gravity to leap up to 20m above the surface. The entire solar-powered robot is compact enough to fit within a 10cm cube, whilst providing unique observation and mission capabilities by creating imagery during the hop. The LunaRoo concept is a proposed payload to fly onboard a Google Lunar XPrize entry. Its compact form is specifically designed for lunar exploration and science mission within the constraints given by PTScientists. The core features of LunaRoo are its method of locomotion - hopping like a kangaroo - and its imaging system capable of unique over-the-horizon perception. The payload will serve as a proof of concept, highlighting the benefits of alternative mobility solutions, in particular enabling observation and exploration of terrain not traversable by wheeled robots. in addition providing data for beyond line-of-sight planning and communications for surface assets, extending overall mission capabilities.
-
Place Categorization and Semantic Mapping on a Mobile Robot Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2016.
 In this paper we focus on the challenging problem of place categorization and semantic mapping on a robot without environment-specific training. Motivated by their ongoing success in various visual recognition tasks, we build our system upon a state-of-the-art convolutional network. We overcome its closed-set limitations by complementing the network with a series of one-vs-all classifiers that can learn to recognize new semantic classes online. Prior domain knowledge is incorporated by embedding the classification system into a Bayesian filter framework that also ensures temporal coherence. We evaluate the classification accuracy of the system on a robot that maps a variety of places on our campus in real-time. We show how semantic information can boost robotic object detection performance and how the semantic map can be used to modulate the robot’s behaviour during navigation tasks. The system is made available to the community as a ROS module.
In this paper we focus on the challenging problem of place categorization and semantic mapping on a robot without environment-specific training. Motivated by their ongoing success in various visual recognition tasks, we build our system upon a state-of-the-art convolutional network. We overcome its closed-set limitations by complementing the network with a series of one-vs-all classifiers that can learn to recognize new semantic classes online. Prior domain knowledge is incorporated by embedding the classification system into a Bayesian filter framework that also ensures temporal coherence. We evaluate the classification accuracy of the system on a robot that maps a variety of places on our campus in real-time. We show how semantic information can boost robotic object detection performance and how the semantic map can be used to modulate the robot’s behaviour during navigation tasks. The system is made available to the community as a ROS module.
2015
Journal Articles
-
Visual Place Recognition: A Survey Transactions on Robotics (TRO), 2015.
 This paper presents a survey of the visual place
recognition research landscape. We start by introducing the
concepts behind place recognition – the role of place recognition
in the animal kingdom, how a “place” is defined in a robotics
context, and the major components of a place recognition system.
We then survey visual place recognition solutions for
environments where appearance change is assumed to be
negligible. Long term robot operations have revealed that
environments continually change; consequently we survey place
recognition solutions that implicitly or explicitly account for
appearance change within the environment. Finally we close with
a discussion of the future of visual place recognition, in particular
with respect to the rapid advances being made in the related
fields of deep learning, semantic scene understanding and video
description.
This paper presents a survey of the visual place
recognition research landscape. We start by introducing the
concepts behind place recognition – the role of place recognition
in the animal kingdom, how a “place” is defined in a robotics
context, and the major components of a place recognition system.
We then survey visual place recognition solutions for
environments where appearance change is assumed to be
negligible. Long term robot operations have revealed that
environments continually change; consequently we survey place
recognition solutions that implicitly or explicitly account for
appearance change within the environment. Finally we close with
a discussion of the future of visual place recognition, in particular
with respect to the rapid advances being made in the related
fields of deep learning, semantic scene understanding and video
description.
-
Superpixel-based appearance change prediction for long-term navigation across seasons Robotics and Autonomous Systems, 2015.
 The goal of our work is to support
existing approaches to place recognition by learning how the
visual appearance of an environment changes over time and by
using this learned knowledge to predict its appearance under
different environmental conditions. We describe the general
idea of appearance change prediction (ACP) and investigate
properties of our novel implementation based on vocabularies
of superpixels (SP-ACP). This paper deepens the
understanding of the proposed SP-ACP system and evaluates
the influence of its parameters. We present the results of a largescale
experiment on the complete 10 hour Nordland dataset and
appearance change predictions between different combinations
of seasons.
The goal of our work is to support
existing approaches to place recognition by learning how the
visual appearance of an environment changes over time and by
using this learned knowledge to predict its appearance under
different environmental conditions. We describe the general
idea of appearance change prediction (ACP) and investigate
properties of our novel implementation based on vocabularies
of superpixels (SP-ACP). This paper deepens the
understanding of the proposed SP-ACP system and evaluates
the influence of its parameters. We present the results of a largescale
experiment on the complete 10 hour Nordland dataset and
appearance change predictions between different combinations
of seasons.
Conference Publications
-
Evaluation of features for leaf classification in challenging conditions In Applications of Computer Vision (WACV), 2015 IEEE Winter Conference on, 2015.
 Fine-grained leaf classification has concentrated on the use of traditional shape and statistical features to classify ideal images. In this paper we evaluate the effectiveness of traditional hand-crafted features and propose the use of deep convolutional neural network (Conv Net) features. We introduce a range of condition variations to explore the robustness of these features, including: translation, scaling, rotation, shading and occlusion. Evaluations on the Flavia dataset demonstrate that in ideal imaging conditions, combining traditional and Conv Net features yields state-of-the art performance with an average accuracy of 97.3%±0:6% compared to traditional features which obtain an average accuracy of 91.2%±1:6%. Further experiments show that this combined classification approach consistently outperforms the best set of traditional features by an average of 5.7% for all of the evaluated condition variations.
Fine-grained leaf classification has concentrated on the use of traditional shape and statistical features to classify ideal images. In this paper we evaluate the effectiveness of traditional hand-crafted features and propose the use of deep convolutional neural network (Conv Net) features. We introduce a range of condition variations to explore the robustness of these features, including: translation, scaling, rotation, shading and occlusion. Evaluations on the Flavia dataset demonstrate that in ideal imaging conditions, combining traditional and Conv Net features yields state-of-the art performance with an average accuracy of 97.3%±0:6% compared to traditional features which obtain an average accuracy of 91.2%±1:6%. Further experiments show that this combined classification approach consistently outperforms the best set of traditional features by an average of 5.7% for all of the evaluated condition variations.
-
Multimodal Deep Autoencoders for Control of a Mobile Robot In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2015.
 Robot navigation systems are typically engineered
to suit certain platforms, sensing suites
and environment types. In order to deploy a
robot in an environment where its existing navigation
system is insufficient, the system must
be modified manually, often at significant cost.
In this paper we address this problem, proposing
a system based on multimodal deep autoencoders
that enables a robot to learn how
to navigate by observing a dataset of sensor input
and motor commands collected while being
teleoperated by a human. Low-level features
and cross modal correlations are learned and
used in initialising two different architectures
with three operating modes. During operation,
these systems exploit the learned correlations
in generating suitable control signals based only
on the sensor information.
Robot navigation systems are typically engineered
to suit certain platforms, sensing suites
and environment types. In order to deploy a
robot in an environment where its existing navigation
system is insufficient, the system must
be modified manually, often at significant cost.
In this paper we address this problem, proposing
a system based on multimodal deep autoencoders
that enables a robot to learn how
to navigate by observing a dataset of sensor input
and motor commands collected while being
teleoperated by a human. Low-level features
and cross modal correlations are learned and
used in initialising two different architectures
with three operating modes. During operation,
these systems exploit the learned correlations
in generating suitable control signals based only
on the sensor information.
-
TripNet: Detecting Trip Hazards on Construction Sites In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2015.
 This paper introduces TripNet, a robotic vision system that detects trip hazards using raw construction site images.
TripNet performs trip hazard identification using only camera imagery and minimal training with a pre-trained Convolutional Neural Network (CNN) rapidly fine-tuned on a small corpus of labelled image regions from construction sites. There is no reliance on prior scene segmentation methods during deployment. Trip-Net achieves comparable performance to a human on a dataset recorded in two distinct real world construction sites. TripNet exhibits spatial and temporal generalization by functioning in previously unseen parts of a construction site and over time periods of several weeks.
This paper introduces TripNet, a robotic vision system that detects trip hazards using raw construction site images.
TripNet performs trip hazard identification using only camera imagery and minimal training with a pre-trained Convolutional Neural Network (CNN) rapidly fine-tuned on a small corpus of labelled image regions from construction sites. There is no reliance on prior scene segmentation methods during deployment. Trip-Net achieves comparable performance to a human on a dataset recorded in two distinct real world construction sites. TripNet exhibits spatial and temporal generalization by functioning in previously unseen parts of a construction site and over time periods of several weeks.
-
Enhancing Human Action Recognition with Region Proposals In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2015.
-
Place Recognition with ConvNet Landmarks: Viewpoint-Robust, Condition-Robust, Training-Free In Proc. of Robotics: Science and Systems (RSS), 2015.
 Here
we present an approach that adapts state-of-the-art object
proposal techniques to identify potential landmarks within an
image for place recognition. We use the astonishing power
of convolutional neural network features to identify matching
landmark proposals between images to perform place recognition
over extreme appearance and viewpoint variations. Our system
does not require any form of training, all components are generic
enough to be used off-the-shelf. We present a range of challenging
experiments in varied viewpoint and environmental conditions.
We demonstrate superior performance to current state-of-the-art
techniques.
[Poster]
Here
we present an approach that adapts state-of-the-art object
proposal techniques to identify potential landmarks within an
image for place recognition. We use the astonishing power
of convolutional neural network features to identify matching
landmark proposals between images to perform place recognition
over extreme appearance and viewpoint variations. Our system
does not require any form of training, all components are generic
enough to be used off-the-shelf. We present a range of challenging
experiments in varied viewpoint and environmental conditions.
We demonstrate superior performance to current state-of-the-art
techniques.
[Poster]
-
On the Performance of ConvNet Features for Place Recognition In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2015.
 This paper comprehensively evaluates
and compares the utility of three state-of-the-art ConvNets on
the problems of particular relevance to navigation for robots;
viewpoint-invariance and condition-invariance, and for the first
time enables real-time place recognition performance using
ConvNets with large maps by integrating a variety of existing
(locality-sensitive hashing) and novel (semantic search space
partitioning) optimization techniques. We present extensive
experiments on four real world datasets cultivated to evaluate
each of the specific challenges in place recognition. The results
demonstrate that speed-ups of two orders of magnitude can
be achieved with minimal accuracy degradation, enabling
real-time performance. We confirm that networks trained for
semantic place categorization also perform better at (specific)
place recognition when faced with severe appearance changes
and provide a reference for which networks and layers are
optimal for different aspects of the place recognition problem.
This paper comprehensively evaluates
and compares the utility of three state-of-the-art ConvNets on
the problems of particular relevance to navigation for robots;
viewpoint-invariance and condition-invariance, and for the first
time enables real-time place recognition performance using
ConvNets with large maps by integrating a variety of existing
(locality-sensitive hashing) and novel (semantic search space
partitioning) optimization techniques. We present extensive
experiments on four real world datasets cultivated to evaluate
each of the specific challenges in place recognition. The results
demonstrate that speed-ups of two orders of magnitude can
be achieved with minimal accuracy degradation, enabling
real-time performance. We confirm that networks trained for
semantic place categorization also perform better at (specific)
place recognition when faced with severe appearance changes
and provide a reference for which networks and layers are
optimal for different aspects of the place recognition problem.
Workshop Publications
-
Sequence Searching with Deep-learnt Depth for Condition-and Viewpoint-invariant Route-based Place Recognition In Workshop on Computer Vision in Vehicle Technology (CVVT), Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
 Vision-based localization on robots and vehicles remains unsolved when extreme appearance change and viewpoint change are present simultaneously. In this paper we significantly improve the viewpoint invariance of the SeqSLAM algorithm by using state-of-the-art deep learning techniques to generate synthetic viewpoints. Our approach is different to other deep learning approaches in that it does not rely on the ability of the CNN network to learn invariant features, but only to produce“good enough” depth images from day-time imagery only. We evaluate the system on a new multi-lane day-night car dataset specifically gathered to simultaneously test both appearance and viewpoint change.
Vision-based localization on robots and vehicles remains unsolved when extreme appearance change and viewpoint change are present simultaneously. In this paper we significantly improve the viewpoint invariance of the SeqSLAM algorithm by using state-of-the-art deep learning techniques to generate synthetic viewpoints. Our approach is different to other deep learning approaches in that it does not rely on the ability of the CNN network to learn invariant features, but only to produce“good enough” depth images from day-time imagery only. We evaluate the system on a new multi-lane day-night car dataset specifically gathered to simultaneously test both appearance and viewpoint change.
-
Continuous Factor Graphs For Holistic Scene Understanding In Workshop on Scene Understanding (SUNw), Intl. Conf. on Computer Vision and Pattern Recognition (CVPR), 2015.
 We propose a novel mathematical formulation for the
holistic scene understanding problem and transform it from
the discrete into the continuous domain. The problem can
then be modeled with a nonlinear continuous factor graph,
and the MAP solution is found via least squares optimization.
We evaluate our method on the realistic NYU2 dataset.
We propose a novel mathematical formulation for the
holistic scene understanding problem and transform it from
the discrete into the continuous domain. The problem can
then be modeled with a nonlinear continuous factor graph,
and the MAP solution is found via least squares optimization.
We evaluate our method on the realistic NYU2 dataset.
-
How Good Are EdgeBoxes, Really? In Workshop on Scene Understanding (SUNw), Intl. Conf. on Computer Vision and Pattern Recognition (CVPR), 2015.
-
SLAM – Quo Vadis? In Support of Object Oriented and Semantic SLAM In Workshop on The Problem of Moving Sensors, Robotics: Science and Systems (RSS), 2015.
 Most current SLAM systems are still based on
primitive geometric features such as points, lines, or planes.
The created maps therefore carry geometric information, but
no immediate semantic information. With the recent significant
advances in object detection and scene classification we think the
time is right for the SLAM community to ask where the SLAM
research should be going during the next years. As a possible
answer to this question, we advocate developing SLAM systems
that are more object oriented and more semantically enriched
than the current state of the art. This paper provides an overview
of our ongoing work in this direction.
Most current SLAM systems are still based on
primitive geometric features such as points, lines, or planes.
The created maps therefore carry geometric information, but
no immediate semantic information. With the recent significant
advances in object detection and scene classification we think the
time is right for the SLAM community to ask where the SLAM
research should be going during the next years. As a possible
answer to this question, we advocate developing SLAM systems
that are more object oriented and more semantically enriched
than the current state of the art. This paper provides an overview
of our ongoing work in this direction.
2014
Conference Publications
-
Phobos and Deimos on Mars – Two Autonomous Robots for the DLR SpaceBot Cup In Proceedings of International Symposium on Artificial Intelligence, Robotics and Automation in Space (iSAIRAS), 2014.
 In 2013, ten teams from German universities and research
institutes participated in a national robot competition
called SpaceBot Cup organized by the DLR Space
Administration. The robots had one hour to autonomously
explore and map a challenging Mars-like environment,
find, transport, and manipulate two objects, and navigate
back to the landing site. Localization without GPS in an
unstructured environment was a major issue as was mobile
manipulation and very restricted communication. This paper describes our system of two rovers operating on the
ground plus a quadrotor UAV simulating an observing orbiting
satellite. We relied on ROS (robot operating system)
as the software infrastructure and describe the main
ROS components utilized in performing the tasks. Despite
(or because of) faults, communication loss and breakdowns,
it was a valuable experience with many lessons
learned.
In 2013, ten teams from German universities and research
institutes participated in a national robot competition
called SpaceBot Cup organized by the DLR Space
Administration. The robots had one hour to autonomously
explore and map a challenging Mars-like environment,
find, transport, and manipulate two objects, and navigate
back to the landing site. Localization without GPS in an
unstructured environment was a major issue as was mobile
manipulation and very restricted communication. This paper describes our system of two rovers operating on the
ground plus a quadrotor UAV simulating an observing orbiting
satellite. We relied on ROS (robot operating system)
as the software infrastructure and describe the main
ROS components utilized in performing the tasks. Despite
(or because of) faults, communication loss and breakdowns,
it was a valuable experience with many lessons
learned.
Workshop Publications
-
Fine-Grained Plant Classification Using Convolutional Neural Networks for Feature Extraction. In CLEF (Working Notes), 2014.
2013
Conference Publications
-
Incremental Sensor Fusion in Factor Graphs with Unknown Delays In Proc. of ESA Symposium on Advanced Space Technologies in Robotics and Automation (ASTRA), 2013.
 Our paper addresses the problem of performing
incremental sensor fusion in factor graphs when
some of the sensor information arrive with a significant
unknown delay. We develop and compare two techniques
to handle such delayed measurements under mild conditions
on the characteristics of that delay: We consider
the unknown delay to be bounded and quantizable into
multiples of the state transition cycle time. The proposed
methods are evaluated using a simulation of a dynamic
3-DoF system that fuses odometry and GPS measurements.
Our paper addresses the problem of performing
incremental sensor fusion in factor graphs when
some of the sensor information arrive with a significant
unknown delay. We develop and compare two techniques
to handle such delayed measurements under mild conditions
on the characteristics of that delay: We consider
the unknown delay to be bounded and quantizable into
multiples of the state transition cycle time. The proposed
methods are evaluated using a simulation of a dynamic
3-DoF system that fuses odometry and GPS measurements.
-
Switchable Constraints and Incremental Smoothing for Online Mitigation of Non-Line-of-Sight and Multipath Effects In Proc. of IEEE Intelligent Vehicles Symposium (IV), 2013.
 Reliable vehicle positioning is a crucial requirement
for many applications of advanced driver assistance
systems. While satellite navigation provides a reasonable performance
in general, it often suffers from multipath and non-line-of-sight
errors when it is applied in urban areas and therefore
does not guarantee consistent results anymore. Our paper
proposes a novel online method that identifies and excludes
the affected pseudorange measurements. Our approach does
not depend on additional sensors, maps, or environmental
models. We rather formulate the positioning problem as a
Bayesian inference problem in a factor graph and combine
the recently developed concept of switchable constraints with
an algorithm for efficient incremental inference in such graphs.
We furthermore introduce the concepts of auxiliary updates and
factor graph pruning in order to accelerate convergence while
keeping the graph size and required runtime bounded. A realworld
experiment demonstrates that the resulting algorithm is
able to successfully localize despite a large number of satellite
observations are influenced by NLOS or multipath effects.
Reliable vehicle positioning is a crucial requirement
for many applications of advanced driver assistance
systems. While satellite navigation provides a reasonable performance
in general, it often suffers from multipath and non-line-of-sight
errors when it is applied in urban areas and therefore
does not guarantee consistent results anymore. Our paper
proposes a novel online method that identifies and excludes
the affected pseudorange measurements. Our approach does
not depend on additional sensors, maps, or environmental
models. We rather formulate the positioning problem as a
Bayesian inference problem in a factor graph and combine
the recently developed concept of switchable constraints with
an algorithm for efficient incremental inference in such graphs.
We furthermore introduce the concepts of auxiliary updates and
factor graph pruning in order to accelerate convergence while
keeping the graph size and required runtime bounded. A realworld
experiment demonstrates that the resulting algorithm is
able to successfully localize despite a large number of satellite
observations are influenced by NLOS or multipath effects.
-
Switchable Constraints vs. Max-Mixture Models vs. RRR – A Comparison of three Approaches to Robust Pose Graph SLAM In Proc. of Intl. Conf. on Robotics and Automation (ICRA), 2013.
 SLAM algorithms that can infer a correct map despite
the presence of outliers have recently attracted increasing
attention. In the context of SLAM, outlier constraints are typically
caused by a failed place recognition due to perceptional
aliasing. If not handled correctly, they can have catastrophic
effects on the inferred map. Since robust robotic mapping and
SLAM are among the key requirements for autonomous longterm
operation, inference methods that can cope with such data
association failures are a hot topic in current research. Our
paper compares three very recently published approaches to
robust pose graph SLAM, namely switchable constraints, maxmixture
models and the RRR algorithm. All three methods were
developed as extensions to existing factor graph-based SLAM
back-ends and aim at improving the overall system’s robustness
to false positive loop closure constraints. Due to the novelty of
the three proposed algorithms, no direct comparison has been
conducted so far.
SLAM algorithms that can infer a correct map despite
the presence of outliers have recently attracted increasing
attention. In the context of SLAM, outlier constraints are typically
caused by a failed place recognition due to perceptional
aliasing. If not handled correctly, they can have catastrophic
effects on the inferred map. Since robust robotic mapping and
SLAM are among the key requirements for autonomous longterm
operation, inference methods that can cope with such data
association failures are a hot topic in current research. Our
paper compares three very recently published approaches to
robust pose graph SLAM, namely switchable constraints, maxmixture
models and the RRR algorithm. All three methods were
developed as extensions to existing factor graph-based SLAM
back-ends and aim at improving the overall system’s robustness
to false positive loop closure constraints. Due to the novelty of
the three proposed algorithms, no direct comparison has been
conducted so far.
-
Incremental Smoothing vs. Filtering for Sensor Fusion on an Indoor UAV In Proc. of Intl. Conf. on Robotics and Automation (ICRA), 2013.
 Our paper explores the performance of a recently proposed incremental smoother in the context of nonlinear sensor fusion for a real-world UAV. This efficient factor graph based smoothing approach has a number of advantages compared to conventional filtering techniques like the EKF or its variants. It can more easily incorporate asynchronous and delayed measurements from sensors operating at different rates and is supposed to be less error-prone in highly nonlinear settings. We compare the novel incremental smoothing approach based on iSAM2 against our conventional EKF based sensor fusion framework. Unlike previously presented work, the experiments are not only performed in simulation, but also on a real-world quadrotor UAV system using IMU, optical flow and altitude measurements.
Our paper explores the performance of a recently proposed incremental smoother in the context of nonlinear sensor fusion for a real-world UAV. This efficient factor graph based smoothing approach has a number of advantages compared to conventional filtering techniques like the EKF or its variants. It can more easily incorporate asynchronous and delayed measurements from sensors operating at different rates and is supposed to be less error-prone in highly nonlinear settings. We compare the novel incremental smoothing approach based on iSAM2 against our conventional EKF based sensor fusion framework. Unlike previously presented work, the experiments are not only performed in simulation, but also on a real-world quadrotor UAV system using IMU, optical flow and altitude measurements.
-
Appearance Change Prediction for Long-Term Navigation Across Seasons In Proceedings of European Conference on Mobile Robotics (ECMR), 2013.
Workshop Publications
-
Predicting the Change – A Step Towards Life-Long Operation in Everyday Environments In Proceedings of Robotics: Science and Systems (RSS) Robotics Challenges and Vision Workshop, 2013.
-
Are We There Yet? Challenging SeqSLAM on a 3000 km Journey Across All Four Seasons. In Proceedings of Workshop on Long-Term Autonomy, IEEE International Conference on Robotics and Automation (ICRA), 2013.
2012
Conference Publications
-
Multipath Mitigation in GNSS-Based Localization using Robust Optimization In Proc. of IEEE Intelligent Vehicles Symposium (IV), 2012.
 Our paper adapts recent advances in the SLAM
(Simultaneous Localization and Mapping) literature to the
problem of multipath mitigation and proposes a novel approach
to successfully localize a vehicle despite a significant
number of multipath observations. We show that GNSS-based
localization problems can be modelled as factor graphs and
solved using efficient nonlinear least squares methods that
exploit the sparsity inherent in the problem formulation. Using
a recently developed novel approach for robust optimization,
satellite observations that are subject to multipath errors can be
successfully identified and rejected during the optimization process.
We demonstrate the feasibility of the proposed approach
on a real-world urban dataset and compare it to an existing
method of multipath detection.
Our paper adapts recent advances in the SLAM
(Simultaneous Localization and Mapping) literature to the
problem of multipath mitigation and proposes a novel approach
to successfully localize a vehicle despite a significant
number of multipath observations. We show that GNSS-based
localization problems can be modelled as factor graphs and
solved using efficient nonlinear least squares methods that
exploit the sparsity inherent in the problem formulation. Using
a recently developed novel approach for robust optimization,
satellite observations that are subject to multipath errors can be
successfully identified and rejected during the optimization process.
We demonstrate the feasibility of the proposed approach
on a real-world urban dataset and compare it to an existing
method of multipath detection.
-
Towards a Robust Back-End for Pose Graph SLAM In Proc. of IEEE Intl. Conf. on Robotics and Automation (ICRA), 2012.
 We propose a novel formulation that allows the back-end
to change parts of the topological structure of the graph
during the optimization process. The back-end can thereby
discard loop closures and converge towards correct solutions
even in the presence of false positive loop closures. This largely
increases the overall robustness of the SLAM system and closes
a gap between the sensor-driven front-end and the back-end
optimizers. We demonstrate the approach and present results
both on large scale synthetic and real-world dataset
We propose a novel formulation that allows the back-end
to change parts of the topological structure of the graph
during the optimization process. The back-end can thereby
discard loop closures and converge towards correct solutions
even in the presence of false positive loop closures. This largely
increases the overall robustness of the SLAM system and closes
a gap between the sensor-driven front-end and the back-end
optimizers. We demonstrate the approach and present results
both on large scale synthetic and real-world dataset
-
Switchable Constraints for Robust Pose Graph SLAM In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2012.
 Current SLAM back-ends are based on least
squares optimization and thus are not robust against outliers
like data association errors and false positive loop closure
detections. Our paper presents and evaluates a robust back-end
formulation for SLAM using switchable constraints. Instead
of proposing yet another appearance-based data association
technique, our system is able to recognize and reject outliers
during the optimization. This is achieved by making
the topology of the underlying factor graph representation
subject to the optimization instead of keeping it fixed. The
evaluation shows that the approach can deal with up to 1000
false positive loop closure constraints on various datasets. This
largely increases the robustness of the overall SLAM system
and closes a gap between the sensor-driven front-end and the
back-end optimizers.
Current SLAM back-ends are based on least
squares optimization and thus are not robust against outliers
like data association errors and false positive loop closure
detections. Our paper presents and evaluates a robust back-end
formulation for SLAM using switchable constraints. Instead
of proposing yet another appearance-based data association
technique, our system is able to recognize and reject outliers
during the optimization. This is achieved by making
the topology of the underlying factor graph representation
subject to the optimization instead of keeping it fixed. The
evaluation shows that the approach can deal with up to 1000
false positive loop closure constraints on various datasets. This
largely increases the robustness of the overall SLAM system
and closes a gap between the sensor-driven front-end and the
back-end optimizers.
-
Towards Robust Graphical Models for GNSS-Based Localization in Urban Environments In Proc. of IEEE International Multi-Conference on Systems, Signals and Devices (SSD), 2012.
Workshop Publications
-
A Generic Approach for Robust Probabilistic Estimation with Graphical Models In Proc. of RSS Workshop on Long-term Operation of Autonomous Robotic Systems in Changing Environments, 2012.
Misc
-
Robust Optimization for Simultaneous Localization and Mapping PhD Thesis. Chemnitz University of Technology 2012.
2011
Conference Publications
-
BRIEF-Gist – Closing the Loop by Simple Means In Proc. of IEEE Intl. Conf. on Intelligent Robots and Systems (IROS), 2011.
-
Autonomous Corridor Flight of a UAV Using a Low-Cost and Light-Weight RGB-D Camera In Proc. of Intl. Symposium on Autonomous Mini Robots for Research and Edutainment (AMiRE), 2011.
 We describe the first application of the novel Kinect RGB-D sensor on a fully autonomous quadrotor UAV. In contrast to the established RGB-D devices that are both expensive and comparably heavy, the Kinect is light-weight and especially low-cost. It provides dense color and depth information and can be readily applied to a variety of tasks in the robotics domain. We apply the Kinect on a UAV in an indoor corridor scenario. The sensor extracts a 3D point cloud of the environment that is further processed on-board to identify walls, obstacles, and the position and orientation of the UAV inside the corridor. Subsequent controllers for altitude, position, velocity, and heading enable the UAV to autonomously operate in this indoor environment.
We describe the first application of the novel Kinect RGB-D sensor on a fully autonomous quadrotor UAV. In contrast to the established RGB-D devices that are both expensive and comparably heavy, the Kinect is light-weight and especially low-cost. It provides dense color and depth information and can be readily applied to a variety of tasks in the robotics domain. We apply the Kinect on a UAV in an indoor corridor scenario. The sensor extracts a 3D point cloud of the environment that is further processed on-board to identify walls, obstacles, and the position and orientation of the UAV inside the corridor. Subsequent controllers for altitude, position, velocity, and heading enable the UAV to autonomously operate in this indoor environment.
-
Autonomous Corridor Flight of a UAV Using an RGB-D Camera In Proc. of EuRobotics RGB-D Workshop on 3D Perception in Robotics, 2011.
 We describe the first application of the novel Kinect RGB-D sensor on a fully autonomous quadrotor UAV. We apply
the UAV in an indoor corridor scenario. The position and
orientation of the UAV inside the corridor is extracted from
the RGB-D data. Subsequent controllers for altitude, posi-
tion, velocity, and heading enable the UAV to autonomously
operate in this indoor environment.
We describe the first application of the novel Kinect RGB-D sensor on a fully autonomous quadrotor UAV. We apply
the UAV in an indoor corridor scenario. The position and
orientation of the UAV inside the corridor is extracted from
the RGB-D data. Subsequent controllers for altitude, posi-
tion, velocity, and heading enable the UAV to autonomously
operate in this indoor environment.
2010
Journal Articles
-
Learning from Nature: Biologically Inspired Robot Navigation and SLAM – A Review Künstliche Intelligenz (German Journal on Artificial Intelligence), Special Issue on SLAM, 2010.
 In this paper we summarize the most important
neuronal fundamentals of navigation in rodents, primates
and humans. We review a number of brain cells that are
involved in spatial navigation and their properties. Furthermore,
we review RatSLAM, a working SLAM system that is
partially inspired by neuronal mechanisms underlying mammalian
spatial navigation.
In this paper we summarize the most important
neuronal fundamentals of navigation in rodents, primates
and humans. We review a number of brain cells that are
involved in spatial navigation and their properties. Furthermore,
we review RatSLAM, a working SLAM system that is
partially inspired by neuronal mechanisms underlying mammalian
spatial navigation.
Conference Publications
-
The Causal Update Filter – A Novel Biologically Inspired Filter Paradigm for Appearance Based SLAM In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), 2010.
 Recently a SLAM algorithm based on biological principles (RatSLAM) has been proposed. It was proven to perform well in large and demanding scenarios. In this paper we establish a comparison of the principles underlying this algorithm with standard probabilistic SLAM approaches and identify the key difference to be an additive update step. Using this insight, we derive the novel, non-Bayesian Causal Update filter that is suitable for application in appearance-based SLAM. We successfully apply this new filter to two demanding vision-only urban SLAM problems of 5 and 66 km length. We show that it can functionally replace the core of RatSLAM, gaining a massive speed-up.
Recently a SLAM algorithm based on biological principles (RatSLAM) has been proposed. It was proven to perform well in large and demanding scenarios. In this paper we establish a comparison of the principles underlying this algorithm with standard probabilistic SLAM approaches and identify the key difference to be an additive update step. Using this insight, we derive the novel, non-Bayesian Causal Update filter that is suitable for application in appearance-based SLAM. We successfully apply this new filter to two demanding vision-only urban SLAM problems of 5 and 66 km length. We show that it can functionally replace the core of RatSLAM, gaining a massive speed-up.
-
Beyond RatSLAM: Improvements to a Biologically Inspired SLAM System In Proc of Intel. Conf. on Emerging Technologies and Factory Automation (ETFA), 2010.
 A SLAM algorithm inspired by biological principles
has been recently proposed and shown to perform well
in a large and demanding scenario. We analyse and compare
this system (RatSLAM) and the established Bayesian
SLAM methods and identify the key difference to be an additive
update step. Using this insight, we derive a novel
filter scheme and successfully show that it can entirely replace
the core of the RatSLAM system while maintaining
its desirable robustness. This leads to a massive speedup,
as the novel filter can be calculated very efficiently.
We successfully applied the new algorithm to the same 66
km long dataset that was used with the original algorithm.
A SLAM algorithm inspired by biological principles
has been recently proposed and shown to perform well
in a large and demanding scenario. We analyse and compare
this system (RatSLAM) and the established Bayesian
SLAM methods and identify the key difference to be an additive
update step. Using this insight, we derive a novel
filter scheme and successfully show that it can entirely replace
the core of the RatSLAM system while maintaining
its desirable robustness. This leads to a massive speedup,
as the novel filter can be calculated very efficiently.
We successfully applied the new algorithm to the same 66
km long dataset that was used with the original algorithm.
-
From Neurons to Robots: Towards Efficient Biologically Inspired Filtering and SLAM In Proc. of KI 2010: Advances in Artificial Intelligence, 2010.
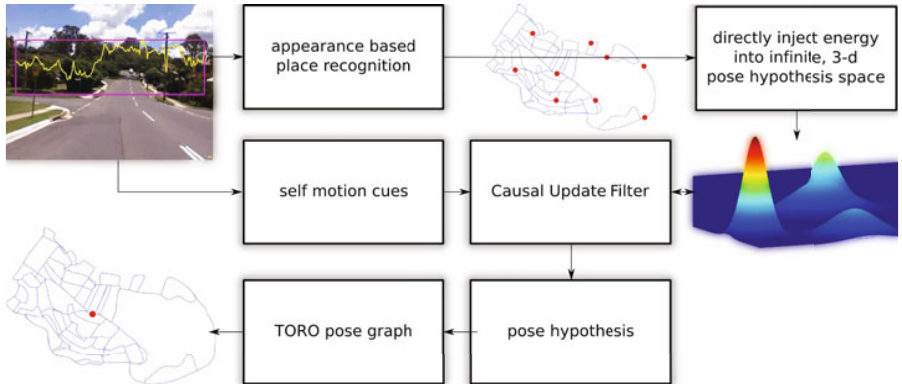 We discuss recently published models of neural information process-
ing under uncertainty and a SLAM system that was inspired by the neural struc-
tures underlying mammalian spatial navigation. We summarize the derivation of
a novel filter scheme that captures the important ideas of the biologically inspired
SLAM approach, but implements them on a higher level of abstraction. This leads
to a new and more efficient approach to biologically inspired filtering which we
successfully applied to real world urban SLAM challenge of 66 km length.
We discuss recently published models of neural information process-
ing under uncertainty and a SLAM system that was inspired by the neural struc-
tures underlying mammalian spatial navigation. We summarize the derivation of
a novel filter scheme that captures the important ideas of the biologically inspired
SLAM approach, but implements them on a higher level of abstraction. This leads
to a new and more efficient approach to biologically inspired filtering which we
successfully applied to real world urban SLAM challenge of 66 km length.
2009
Conference Publications
-
A Vision Based Onboard Approach for Landing and Position Control of an Autonomous Multirotor UAV in GPS-Denied Environments In Proc. of Intl. Conf. on Advanced Robotics (ICAR), 2009.
 We describe our work on multirotor UAVs and
focus on our method for autonomous landing and position
control. The paper describes the design of our landing pad
and the vision based detection algorithm that estimates the 3Dposition
of the UAV relative to the landing pad. A cascaded
controller structure stabilizes velocity and position in the
absence of GPS signals by using a dedicated optical flow sensor.
Practical experiments prove the quality of our approach.
We describe our work on multirotor UAVs and
focus on our method for autonomous landing and position
control. The paper describes the design of our landing pad
and the vision based detection algorithm that estimates the 3Dposition
of the UAV relative to the landing pad. A cascaded
controller structure stabilizes velocity and position in the
absence of GPS signals by using a dedicated optical flow sensor.
Practical experiments prove the quality of our approach.
-
Using Image Profiles and Integral Images for Efficient Calculation of Sparse Optical Flow Fields. In Proceedings of the International Conference on Advanced Robotics, 2009.
2008
Conference Publications
-
Autonomous Landing for a Multirotor UAV Using Vision In Workshop Proc. of SIMPAR 2008 Intl. Conf. on Simulation, Modeling and Programming for Autonomous Robots, 2008.
 We describe our work on multirotor UAVs and focus on our
method for autonomous landing. The paper describes the design of our
landing pad and its advantages. We explain how the landing pad detection
algorithm works and how the 3D-position of the UAV relative to
the landing pad is calculated. Practical experiments prove the quality of
these estimations.
We describe our work on multirotor UAVs and focus on our
method for autonomous landing. The paper describes the design of our
landing pad and its advantages. We explain how the landing pad detection
algorithm works and how the 3D-position of the UAV relative to
the landing pad is calculated. Practical experiments prove the quality of
these estimations.
2007
Conference Publications
-
Using the Unscented Kalman Filter in Mono-SLAM with Inverse Depth Parametrization for Autonomous Airship Control In Proc. of IEEE International Workshop on Safety Security and Rescue Robotics (SSRR), 2007.
 In this paper, we present an approach for aiding control of an autonomous airship by the means of SLAM. We show how the Unscented Kalman Filter can be applied in a SLAM context with monocular vision. The recently published Inverse Depth Parametrization is used for undelayed single-hypothesis landmark initialization and modelling. The novelty of the presented approach lies in the combination of UKF, Inverse Depth Parametrization and bearing-only SLAM and its application for autonomous airship control and UAV control in general.
In this paper, we present an approach for aiding control of an autonomous airship by the means of SLAM. We show how the Unscented Kalman Filter can be applied in a SLAM context with monocular vision. The recently published Inverse Depth Parametrization is used for undelayed single-hypothesis landmark initialization and modelling. The novelty of the presented approach lies in the combination of UKF, Inverse Depth Parametrization and bearing-only SLAM and its application for autonomous airship control and UAV control in general.
-
FastSLAM using SURF Features: An Efficient Implementation and Practical Experiences In Proceedings of the International Conference on Intelligent and Autonomous Vehicles, IAV07, 2007.
-
Comparing several implementations of two recently published feature detectors In Proceedings of the International Conference on Intelligent and Autonomous Vehicles, IAV07, 2007.
Misc
-
Stereo Odometry – A Review of Approaches 2007.
2006
Conference Publications
-
Bringing Robotics Closer to Students – A Threefold Approach In Proc. of Intl. Conf. on Robotics and Automation (ICRA), 2006.
-
Using and Extending the Miro Middleware for Autonomous Mobile Robots In Proceedings of Towards Autonomous Robotic Systems (TAROS06), 2006.
-
Towards Using Bundle Adjustment for Robust Stereo Odometry in Outdoor Terrain In Proceedings of Towards Autonomous Robotic Systems (TAROS06), 2006.
Misc
-
Stereo Odometry on an Autonomous Mobile Robot in Outdoor Terrain (Diplomarbeit) 2006.
2005
Conference Publications
-
RoboKing - Bringing Robotics Closer to Pupils In Proc. of Intl. Conf. on Robotics and Automation (ICRA), 2005.
-
Visual Odometry using Sparse Bundle Adjustment on an Autonomous Outdoor Vehicle In Tagungsband Autonome Mobile Systeme 2005, 2005.
Workshop Publications
-
Comparison of Stereovision Odometry Approaches. In Proceedings of IEEE International Conference on Robotics and Automation, Planetary Rover Workshop, 2005.