Visual Place Recognition in Changing Environments
The picture below illustrates the idea of place recognition: An autonomous robot that operates in an environment (for example our university campus) should be able to recognize different places when it comes back to them after some time. This is important to support reliable navigation, mapping, and localisation. Robust place recognition is therefore a crucial capability for an autonomous robot.
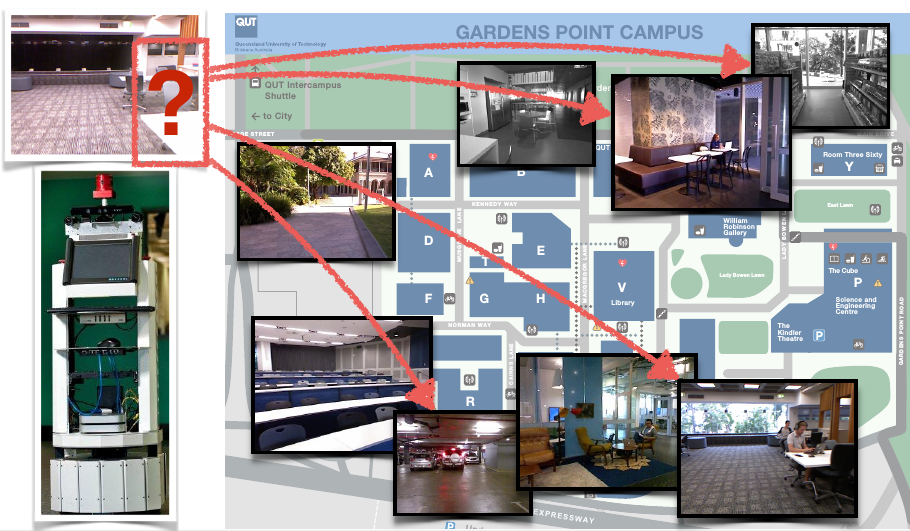

The problem of visual place recognition gets challenging if the visual appearance of these places changed in the meantime. This usually happens due to changes in the lighting conditions (think day vs. night or early morning vs. late afternoon), shadows, different weather conditions, or even different seasons. We develop algorithms for vision-based place recognition that can deal with these changes in visual appearance.
A general overview of the topic can be found in our survey paper:
-
Visual Place Recognition: A Survey Transactions on Robotics (TRO), 2015.
 This paper presents a survey of the visual place
recognition research landscape. We start by introducing the
concepts behind place recognition – the role of place recognition
in the animal kingdom, how a “place” is defined in a robotics
context, and the major components of a place recognition system.
We then survey visual place recognition solutions for
environments where appearance change is assumed to be
negligible. Long term robot operations have revealed that
environments continually change; consequently we survey place
recognition solutions that implicitly or explicitly account for
appearance change within the environment. Finally we close with
a discussion of the future of visual place recognition, in particular
with respect to the rapid advances being made in the related
fields of deep learning, semantic scene understanding and video
description.
This paper presents a survey of the visual place
recognition research landscape. We start by introducing the
concepts behind place recognition – the role of place recognition
in the animal kingdom, how a “place” is defined in a robotics
context, and the major components of a place recognition system.
We then survey visual place recognition solutions for
environments where appearance change is assumed to be
negligible. Long term robot operations have revealed that
environments continually change; consequently we survey place
recognition solutions that implicitly or explicitly account for
appearance change within the environment. Finally we close with
a discussion of the future of visual place recognition, in particular
with respect to the rapid advances being made in the related
fields of deep learning, semantic scene understanding and video
description.
Convolutional Networks for Place Recognition under Challenging Conditions (ongoing since 2014)
In two papers published at RSS and IROS 2015 we explored how Convolutional Networks can be utilized for robust visual place recognition. We found that the features from middle layers of these networks are robust against appearance changes and can be used as change-robust landmark descriptors. Since then, Sourav Garg has pushed the topic forward with publications at ICRA and RSS 2018.
Publications
-
Probabilistic Appearance-Invariant Topometric Localization with New Place Awareness IEEE Robotics and Automation Letters (RA-L), 2021.
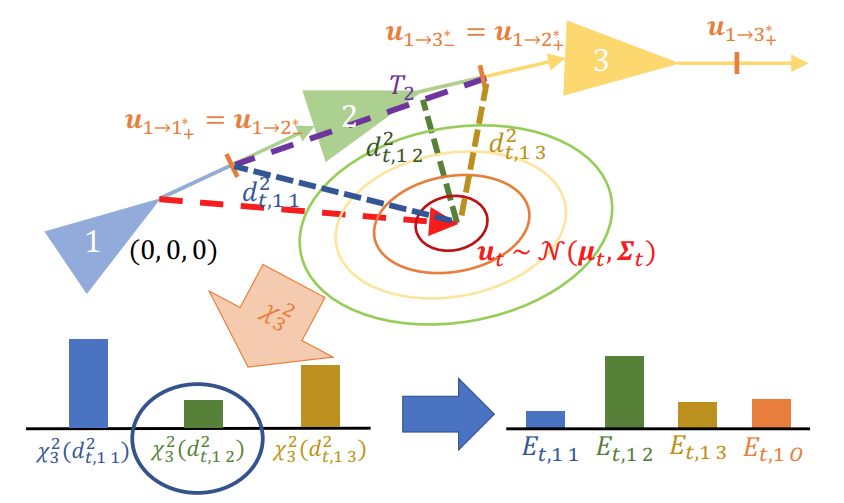 We present a new probabilistic topometric localization system which incorporates full 3-dof odometry into the motion model and furthermore, adds an “off-map” state within the state-estimation framework, allowing query traverses which feature significant route detours from the reference map to be successfully localized. We perform extensive evaluation on multiple query traverses from the Oxford RobotCar dataset exhibiting both significant appearance change and deviations from routes previously traversed.
[arXiv]
We present a new probabilistic topometric localization system which incorporates full 3-dof odometry into the motion model and furthermore, adds an “off-map” state within the state-estimation framework, allowing query traverses which feature significant route detours from the reference map to be successfully localized. We perform extensive evaluation on multiple query traverses from the Oxford RobotCar dataset exhibiting both significant appearance change and deviations from routes previously traversed.
[arXiv]
-
Probabilistic Visual Place Recognition for Hierarchical Localization IEEE Robotics and Automation Letters (RA-L), 2021.
 We propose two methods which adapt image retrieval techniques used for visual place recognition to the Bayesian state estimation formulation for localization. We demonstrate significant improvements to the
localization accuracy of the coarse localization stage using our methods, whilst retaining state-of-the-art performance under severe appearance change. Using extensive experimentation on the Oxford RobotCar dataset, results show that our approach
outperforms comparable state-of-the-art methods in terms of precision-recall performance for localizing image sequences. In addition, our proposed methods provides the flexibility
to contextually scale localization latency in order to achieve these improvements.
[arXiv]
We propose two methods which adapt image retrieval techniques used for visual place recognition to the Bayesian state estimation formulation for localization. We demonstrate significant improvements to the
localization accuracy of the coarse localization stage using our methods, whilst retaining state-of-the-art performance under severe appearance change. Using extensive experimentation on the Oxford RobotCar dataset, results show that our approach
outperforms comparable state-of-the-art methods in terms of precision-recall performance for localizing image sequences. In addition, our proposed methods provides the flexibility
to contextually scale localization latency in order to achieve these improvements.
[arXiv]
-
Semantic–geometric visual place recognition: a new perspective for reconciling opposing views The International Journal of Robotics Research (IJRR), 2022.
 We propose a hybrid image descriptor that semantically aggregates salient visual information, complemented by appearance-based description, and augment a conventional coarse-to-fine recognition pipeline with keypoint correspondences extracted from within the convolutional feature maps of a pre-trained network. Finally, we introduce descriptor normalization and local score enhancement strategies for improving the robustness of the system. Using both existing benchmark datasets and extensive new datasets that for the first time combine the three challenges of opposing viewpoints, lateral viewpoint shifts, and extreme appearance change, we show that our system can achieve practical place recognition performance where existing state-of-the-art methods fail.
We propose a hybrid image descriptor that semantically aggregates salient visual information, complemented by appearance-based description, and augment a conventional coarse-to-fine recognition pipeline with keypoint correspondences extracted from within the convolutional feature maps of a pre-trained network. Finally, we introduce descriptor normalization and local score enhancement strategies for improving the robustness of the system. Using both existing benchmark datasets and extensive new datasets that for the first time combine the three challenges of opposing viewpoints, lateral viewpoint shifts, and extreme appearance change, we show that our system can achieve practical place recognition performance where existing state-of-the-art methods fail.
-
Look No Deeper: Recognizing Places from Opposing Viewpoints under Varying Scene Appearance using Single-View Depth Estimation In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2019.
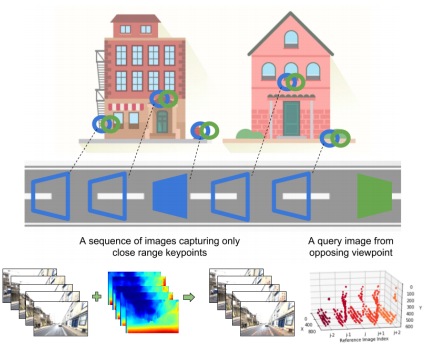 We present a new depth-and temporal-aware visual place recognition system that solves the opposing viewpoint, extreme appearance-change visual place recognition problem. Our system performs sequence-to-single matching by extracting depth-filtered keypoints using a state-of-the-art depth estimation pipeline, constructing a keypoint sequence over multiple frames from the reference dataset, and comparing those keypoints to those in a single query image. We evaluate the system on a challenging benchmark dataset and show that it consistently outperforms state-of-the-art techniques. We also develop a range of diagnostic simulation experiments that characterize the contribution of depth-filtered keypoint sequences with respect to key domain parameters including degree of appearance change and camera motion.
[arXiv]
We present a new depth-and temporal-aware visual place recognition system that solves the opposing viewpoint, extreme appearance-change visual place recognition problem. Our system performs sequence-to-single matching by extracting depth-filtered keypoints using a state-of-the-art depth estimation pipeline, constructing a keypoint sequence over multiple frames from the reference dataset, and comparing those keypoints to those in a single query image. We evaluate the system on a challenging benchmark dataset and show that it consistently outperforms state-of-the-art techniques. We also develop a range of diagnostic simulation experiments that characterize the contribution of depth-filtered keypoint sequences with respect to key domain parameters including degree of appearance change and camera motion.
[arXiv]
-
LoST? Appearance-Invariant Place Recognition for Opposite Viewpoints using Visual Semantics In Proc. of Robotics: Science and Systems (RSS), 2018.
In this paper we develop a suite of novel semantic- and appearance-based techniques to enable for the first time high performance place recognition in the challenging scenario of recognizing places when returning from the opposite direction. We first propose a novel Local Semantic Tensor (LoST) descriptor of images using the convolutional feature maps from a state-of-the-art dense semantic segmentation network. Then, to verify the spatial semantic arrangement of the top matching candidates, we develop a novel approach for mining semantically-salient keypoint correspondences.
-
Don’t Look Back: Robustifying Place Categorization for Viewpoint- and Condition-Invariant Place Recognition In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2018.
 In this work, we develop a novel methodology for using the semantics-aware
higher-order layers of deep neural networks for recognizing
specific places from within a reference database. To further
improve the robustness to appearance change, we develop a
descriptor normalization scheme that builds on the success of
normalization schemes for pure appearance-based techniques.
In this work, we develop a novel methodology for using the semantics-aware
higher-order layers of deep neural networks for recognizing
specific places from within a reference database. To further
improve the robustness to appearance change, we develop a
descriptor normalization scheme that builds on the success of
normalization schemes for pure appearance-based techniques.
-
Place Recognition with ConvNet Landmarks: Viewpoint-Robust, Condition-Robust, Training-Free In Proc. of Robotics: Science and Systems (RSS), 2015.
 Here
we present an approach that adapts state-of-the-art object
proposal techniques to identify potential landmarks within an
image for place recognition. We use the astonishing power
of convolutional neural network features to identify matching
landmark proposals between images to perform place recognition
over extreme appearance and viewpoint variations. Our system
does not require any form of training, all components are generic
enough to be used off-the-shelf. We present a range of challenging
experiments in varied viewpoint and environmental conditions.
We demonstrate superior performance to current state-of-the-art
techniques.
[Poster]
Here
we present an approach that adapts state-of-the-art object
proposal techniques to identify potential landmarks within an
image for place recognition. We use the astonishing power
of convolutional neural network features to identify matching
landmark proposals between images to perform place recognition
over extreme appearance and viewpoint variations. Our system
does not require any form of training, all components are generic
enough to be used off-the-shelf. We present a range of challenging
experiments in varied viewpoint and environmental conditions.
We demonstrate superior performance to current state-of-the-art
techniques.
[Poster]
-
On the Performance of ConvNet Features for Place Recognition In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2015.
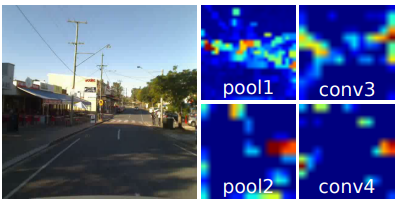 This paper comprehensively evaluates
and compares the utility of three state-of-the-art ConvNets on
the problems of particular relevance to navigation for robots;
viewpoint-invariance and condition-invariance, and for the first
time enables real-time place recognition performance using
ConvNets with large maps by integrating a variety of existing
(locality-sensitive hashing) and novel (semantic search space
partitioning) optimization techniques. We present extensive
experiments on four real world datasets cultivated to evaluate
each of the specific challenges in place recognition. The results
demonstrate that speed-ups of two orders of magnitude can
be achieved with minimal accuracy degradation, enabling
real-time performance. We confirm that networks trained for
semantic place categorization also perform better at (specific)
place recognition when faced with severe appearance changes
and provide a reference for which networks and layers are
optimal for different aspects of the place recognition problem.
This paper comprehensively evaluates
and compares the utility of three state-of-the-art ConvNets on
the problems of particular relevance to navigation for robots;
viewpoint-invariance and condition-invariance, and for the first
time enables real-time place recognition performance using
ConvNets with large maps by integrating a variety of existing
(locality-sensitive hashing) and novel (semantic search space
partitioning) optimization techniques. We present extensive
experiments on four real world datasets cultivated to evaluate
each of the specific challenges in place recognition. The results
demonstrate that speed-ups of two orders of magnitude can
be achieved with minimal accuracy degradation, enabling
real-time performance. We confirm that networks trained for
semantic place categorization also perform better at (specific)
place recognition when faced with severe appearance changes
and provide a reference for which networks and layers are
optimal for different aspects of the place recognition problem.
Predicting Appearance Changes (2013 – 2015)
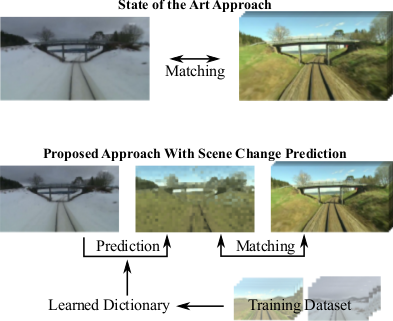 In earlier work, conducted at TU Chemnitz with colleagues Peer Neubert and Peter Protzel, we explored the possibilities of predicting the visual changes in appearance between different seasons.
In earlier work, conducted at TU Chemnitz with colleagues Peer Neubert and Peter Protzel, we explored the possibilities of predicting the visual changes in appearance between different seasons.
This is a more active approach to robust place recognition, since it aims at reaching robustness not by becoming invariant to changes, but rather learn them from experience, and use the learned model to predict how a place would appear under different conditions (e.g. in winter or in summer).
Coming from the pre-deep learning era, our results look rather coarse. A number of groups have applied generative adverserial networks (GANs) to this problem and achieved far more superior results.
Publications
-
Superpixel-based appearance change prediction for long-term navigation across seasons Robotics and Autonomous Systems, 2015.
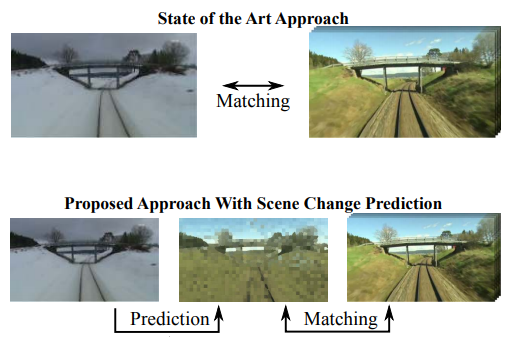 The goal of our work is to support
existing approaches to place recognition by learning how the
visual appearance of an environment changes over time and by
using this learned knowledge to predict its appearance under
different environmental conditions. We describe the general
idea of appearance change prediction (ACP) and investigate
properties of our novel implementation based on vocabularies
of superpixels (SP-ACP). This paper deepens the
understanding of the proposed SP-ACP system and evaluates
the influence of its parameters. We present the results of a largescale
experiment on the complete 10 hour Nordland dataset and
appearance change predictions between different combinations
of seasons.
The goal of our work is to support
existing approaches to place recognition by learning how the
visual appearance of an environment changes over time and by
using this learned knowledge to predict its appearance under
different environmental conditions. We describe the general
idea of appearance change prediction (ACP) and investigate
properties of our novel implementation based on vocabularies
of superpixels (SP-ACP). This paper deepens the
understanding of the proposed SP-ACP system and evaluates
the influence of its parameters. We present the results of a largescale
experiment on the complete 10 hour Nordland dataset and
appearance change predictions between different combinations
of seasons.
-
Appearance Change Prediction for Long-Term Navigation Across Seasons In Proceedings of European Conference on Mobile Robotics (ECMR), 2013.
-
Are We There Yet? Challenging SeqSLAM on a 3000 km Journey Across All Four Seasons. In Proceedings of Workshop on Long-Term Autonomy, IEEE International Conference on Robotics and Automation (ICRA), 2013.
-
Predicting the Change – A Step Towards Life-Long Operation in Everyday Environments In Proceedings of Robotics: Science and Systems (RSS) Robotics Challenges and Vision Workshop, 2013.
BRIEF-Gist (2011)
-
BRIEF-Gist – Closing the Loop by Simple Means In Proc. of IEEE Intl. Conf. on Intelligent Robots and Systems (IROS), 2011.