Due to the COVID-19 crisis, ICRA 2020 has become a fully virtual conference and this workshop is being held in virtual form in the week of 22-26 June 2020.
Invited Talks
Please join our Slack channel for discussions and questions.
Chasing a Chimera: from SLAM to Real-time High-level Understanding by Luca Carlone (MIT SPARK Lab)
The Robotic Vision Scene Understanding Challenge by David Hall (QUT Centre for Robotics)
Scene Understanding Challenge – Call for Participation
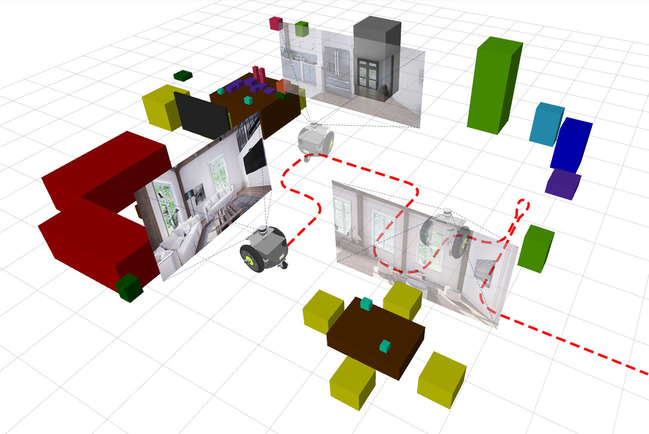
The Robotic Vision Scene Understanding Challenge evaluates how well a robotic vision system can understand the semantic and geometric aspects of its environment. The challenge consists of two distinct tasks: Object-based Semantic SLAM, and Scene Change Detection.
The challenge is open for submissions since June 2020 and will close 1 September 2020. A cash prize of $2,500USD is available for the best participants.
Interested? Please read our dedicated website for more information about the challenge and how to participate. The video below provides a quick overview.
Organisers
The Robotic Vision Challenges organisers are with the Australian Centre for Robotic Vision at Queensland University of Technology (QUT), Monash University, the University of Adelaide, and Google AI.




Queensland University of Technology
Queensland University of Technology
Google Brain
Google Brain




Imperial College London
University of Adelaide
University of Adelaide
George Mason University
Sponsors and Supporters
