CVPR 2023 WS: Embodied AI - Robotic Vision Scene Understanding Challenge (RVSU)
News
- 19 June 2023 Embodied AI CVPR Workshop
- 06 June 2023 Winning teams announced
- 02 May 2023 Challenge submission date extended to May 27th
- 15 March 2023 Challenge officially launched alongside Embodied AI Workshop! Evaluation page now up and running on EvalAI
- 18 January 2023 Prizes announced for 2023 challenge. 18 January 2023 Prizes announced for 2023 challenge. 1 RTX A6000 and up to 5 Jetson Nanos to be awarded for each of the top two teams.
- 16 Dec 2022 Embodied AI workshop confirmed for CVPR2023 hosting the latest Scene Understanding Challenge. Workshop date - June 19th 2023.
Overview
~ Registration is now closed ~
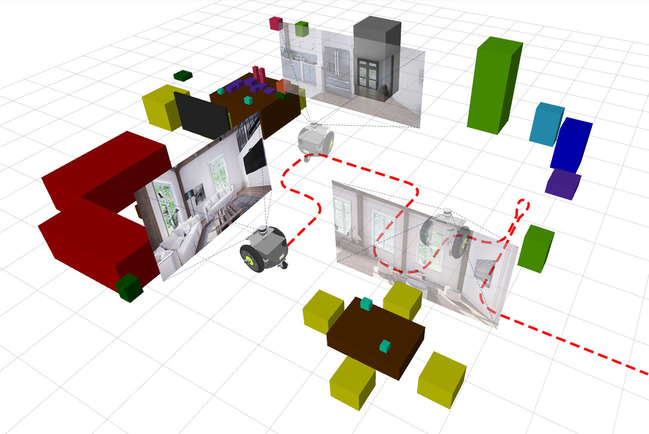
The CVPR2023 Embodied AI Workshop of our Robotic Vision Scene Understanding Challenge evaluates how well a robotic vision system can understand the semantic and geometric aspects of its environment. The challenge consists of two distinct tasks: Object-based Semantic SLAM, and Scene Change Detection.
Key features of this challenge include:
- GPU Prizes sponsored by NVIDIA - 1 RTX A6000 and up to 5 Jetson Nanos to be awarded for each of the top two teams.
- BenchBot, a complete software stack for running robotic systems in simulation and the real world
- Running algorithms in realistic 3D simulation with only a few lines of Python code
- The BenchBot API, which allows simple interfacing with robots while supporting both OpenAI Gym-style and simple object-oriented Agent approaches
- Easy-to-use scripts for running simulated environments, executing code on a simulated robot, evaluating semantic scene understanding results, and automating code execution across multiple environments
- Use of NVIDIA’s Omniverse-powered Isaac Simulator for interfacing with, and simulation of, high fidelity 3D environments
Submit your results to EvalAI - Main challenge evaluation servers opening Feb 2023!
Watch the video below to learn more!
Challenge Results
The top two teams this year are
- Team MSCLab -> Korean Advanced Institute of Science and Technology (KAIST) -> Paper
- Team SP -> Tata Consultancy Services (TCS) Research -> Paper (TBA) Details to be provided during CVPR 2023 Embodied AI workshop.
Challenge Task Details
This year, the semantic scene understanding challenge is split into 2 modes, across 2 different semantic scene understanding tasks, for a total of 4 different challenge variations. This year we are not including the passive navigation scene understanding track to place greater emphasis on active embodied agents exploring a scene than in previous iterations of the challenge.
The two different semantic scene understanding tasks are:
- Semantic SLAM: Participants use a robot to traverse around the environment, building up an object-based semantic map from the robot’s RGBD sensor observations and odomtry measurements.
- Scene change detection (SCD): Participants use a robot to traverse through an environment scene, building up a semantic understanding of the scene. Then the robot is moved to a new start position in the same environment, but with different conditions. Along with a possible change from day to night, the new scene has a number objects added and / or removed. Participants must produce an object-based semantic map describing the changes between the two scenes.
The object-based semantic maps generated by submissions are evaluated against the corresponding ground-truth object-based semantic map (for task 2 this is the map of changes in the second scene, with respect to the first). Please see the BenchBot Evaluation documentation for details on object-based semantic maps submission formats, and further explanation of the two different tasks.
Each task has 2 variations, corresponding to the following modes:
- Active control, with ground-truth localisation (AGT): The robot can be controlled by either moving forward a requested distance, or rotating on the spot a requested number of degrees. The task cannot be continued if the robot collides with the environment. Participants receive ground-truth poses for all robot components after each action.
- Active control, using dead reckoning (i.e. no localisation) (ADR): The robot can be controlled by either moving forward a requested distance, or rotating on the spot a requested number of degrees. Participants receive poses derived from robot odometry after each action, with localisation error that accumulates over time. Robot movement is also done based on noisy odometry rather than ground truth, providing noise in movement as well as provided poses.
Please see the BenchBot API documentation for full details about what actions and observations are available in each mode, and how to use them with your semantic scene understanding algorithms.
Note that passive mode (as seen in past challenges) is available on the evaluation servers for algorithm development but will not be considered when awarding prizes as part of the main challenge.
How to Participate
Participation in 2023 challenge is now closed. Instructions below apply for submitting to continuous evaluation server.
The challenge participation page is available on the EvalAI website, and will be open until the challenge closes in May. Please create an account, sign in, & click the “Participate” tab to enter our challenge. Full details on how to participate, the available software framework, and submission requirements are provided on the site.
Participating in the Semantic Scene Understanding Challenge is as simple as the steps below. The BenchBot software stack is designed from the ground up to eliminate as many obstacles as possible, so you can focus on what matters: solving semantic scene understanding problems. A collection of resources, documentation, and examples are also available within the BenchBot ecosystem to support your experience while participating in the challenge.
To participate in our challenge:
- Download & install the BenchBot software stack. Use the examples to dive straight in & start playing (benchbot_run –list-examples)
- Choose a task to start working on a solution for, using
benchbot_run --list-tasksto list supported tasks - Start with the development environments “miniroom” and “house” which include ground-truth maps to aid in your algorithm development
- Develop a solution using the
benchbot_run,benchbot_submit, &benchbot_evalscripts - Create some results for your solution in the challenge environments using:
benchbot_batch -r carter -t <your_task> -E <batch_name> -z -n <your_submission_cmd> - Use the Submit tab at the top of our EvalAI page to submit your results for evaluation
Participants need to provide a short summary of their method at submission time. Each participant is also encouraged to write a short paper (approx 4 pages) outlining the technique which was used in the challenge. These aren’t required at the same time as the initial submission but will be made available to the general public through our challenge website. Please submit summaries and papers by e-mail to contact@roboticvisionchallenge.org.
Challenge Prizes
1 RTX A6000 and up to 5 Jetson Nanos (1 for each member) for each of the top 2 winning teams.
Important Dates
- 15 March - Challenge launch
- 27 May - Submissions due
- 19 June - CVPR 2023 Embodied AI workshop
Workshop Details
Our Robotic Vision Scene Understanding Challenge is part of the CVPR 2023 Embodied AI workshop. Please check out the workshop website for more details and for information about other robotic vision/embodied AI challenges being run.
Questions?
Talk to us on Slack or contact us via email at contact@roboticvisionchallenge.org.
Organisers, Support, and Acknowledgements
Stay in touch and follow us on Twitter for news and announcements: @robVisChallenge.



Queensland University of Technology
Queensland University of Technology
The Robotic Vision Challenges organisers have been associated with the Australian Centre for Robotic Vision and QUT Centre for Robotics at Queensland University of Technology (QUT) in Brisbane, Australia. In 2023 David Hall has continued work on the challenges, supported by the Commonwealth Scientific and Industrial Research Organisation (CSIRO) Machine Learning and Artificial Intelligence Future Science Platform (MLAI FSP).
We thank the following supporters of this work:

