Scene Understanding, Semantic SLAM, Implicit Representations
Making a robot understand what it sees is a fascinating goal in my current research. In the past we developed novel methods for Semantic Mapping and SLAM by combining object detection with simultaneous localisation and mapping (SLAM) techniques, representing the environment as a scene graph. More recently, we have investigated a fresh take on the problem and represent the environment with NeRFs or Gaussian Splatting.
Join us for your PhD!
If you want to do a PhD with us in this area, read more information here.
Representations with NeRFs and Gaussian Splatting
-
Real-is-Sim: Bridging the Sim-to-Real Gap with a Dynamic Digital Twin for Real-World Robot Policy Evaluation arXiv preprint arXiv:2504.03597, 2025.
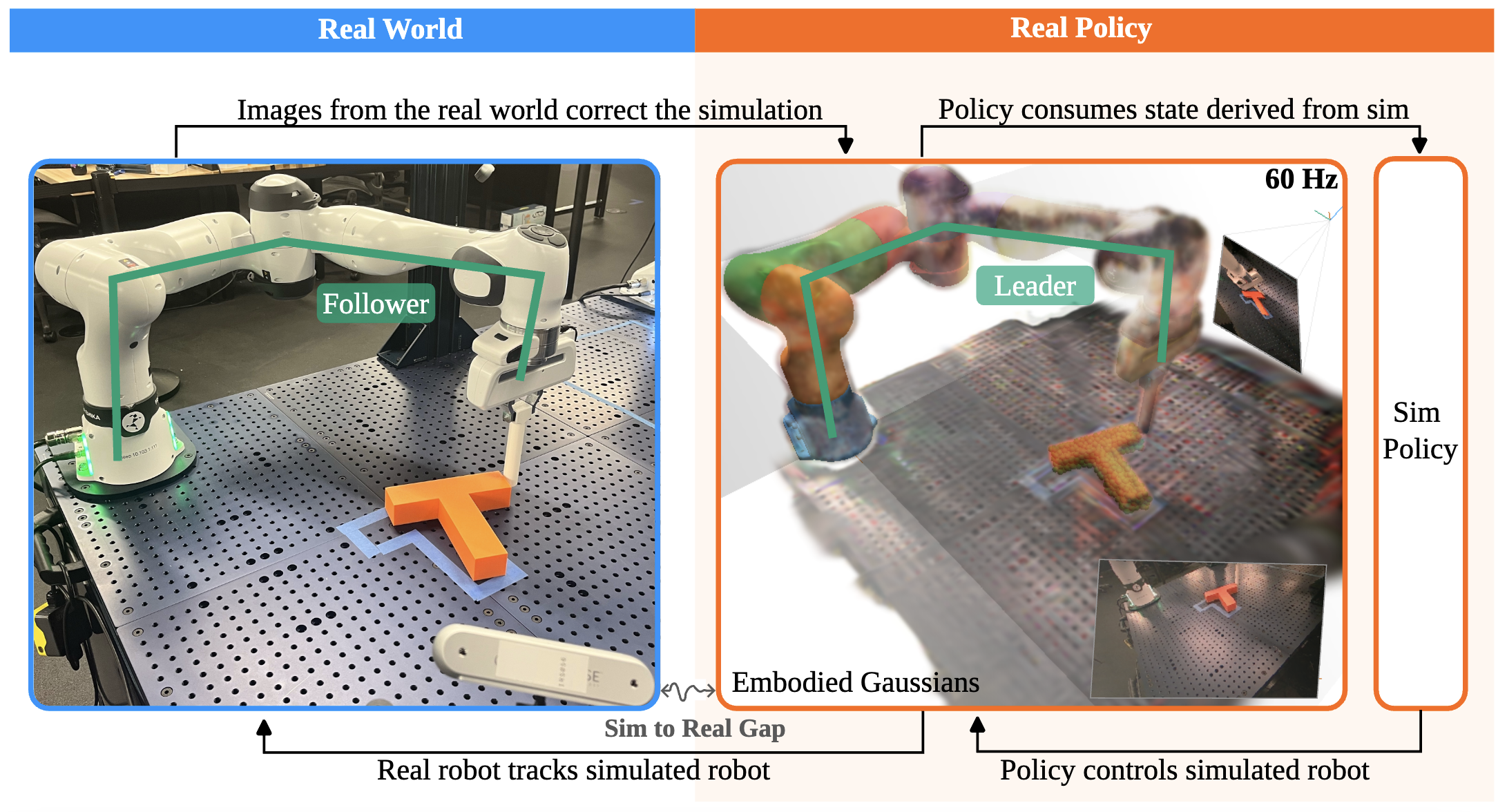 We introduce real-is-sim, a new approach to integrating simulation into behavior cloning pipelines. In contrast to real-only methods, which lack the ability to safely test policies before deployment, and sim-to-real methods, which require complex adaptation to cross the sim-to-real gap, our framework allows policies to seamlessly switch between running on real hardware and running in parallelized virtual environments. At the center of real-is-sim is a dynamic digital twin, powered by the Embodied Gaussian simulator, that synchronizes with the real world at 60Hz. This twin acts as a mediator between the behavior cloning policy and the real robot. Policies are trained using representations derived from simulator states and always act on the simulated robot, never the real one. During deployment, the real robot simply follows the simulated robot’s joint states, and the simulation is continuously corrected with real world measurements. This setup, where the simulator drives all policy execution and maintains real-time synchronization with the physical world, shifts the responsibility of crossing the sim-to-real gap to the digital twin’s synchronization mechanisms, instead of the policy itself.
[arXiv]
[website]
We introduce real-is-sim, a new approach to integrating simulation into behavior cloning pipelines. In contrast to real-only methods, which lack the ability to safely test policies before deployment, and sim-to-real methods, which require complex adaptation to cross the sim-to-real gap, our framework allows policies to seamlessly switch between running on real hardware and running in parallelized virtual environments. At the center of real-is-sim is a dynamic digital twin, powered by the Embodied Gaussian simulator, that synchronizes with the real world at 60Hz. This twin acts as a mediator between the behavior cloning policy and the real robot. Policies are trained using representations derived from simulator states and always act on the simulated robot, never the real one. During deployment, the real robot simply follows the simulated robot’s joint states, and the simulation is continuously corrected with real world measurements. This setup, where the simulator drives all policy execution and maintains real-time synchronization with the physical world, shifts the responsibility of crossing the sim-to-real gap to the digital twin’s synchronization mechanisms, instead of the policy itself.
[arXiv]
[website]
-
Multi-View Pose-Agnostic Change Localization with Zero Labels In Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
 We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn additional change channels in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7 and 1.6 improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
[arXiv]
We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn additional change channels in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7 and 1.6 improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
[arXiv]
-
Physically Embodied Gaussian Splatting: A Realtime Correctable World Model for Robotics In Conference on Robot Learning (CoRL), 2024. Oral Presentation
 We propose a novel dual "Gaussian-Particle" representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates "visual forces" that correct the particle positions while respecting known physical constraints. By integrating predictive physical modeling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality.
[arXiv]
[website]
We propose a novel dual "Gaussian-Particle" representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates "visual forces" that correct the particle positions while respecting known physical constraints. By integrating predictive physical modeling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality.
[arXiv]
[website]
-
Physically Embodied Gaussian Splatting: Embedding Physical Priors Into a Visual 3d World Model for Robotics In Workshop for Neural Representation Learning for Robot Manipulation, Conference on Robot Learning (CoRL), 2023.
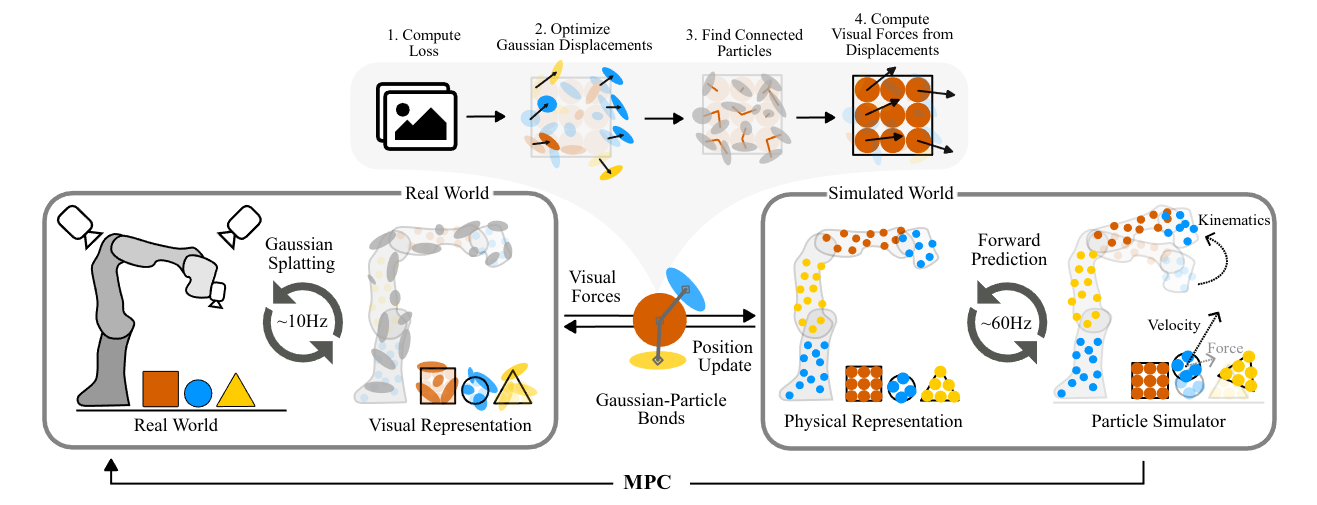 Our dual Gaussian-Particle representation captures visual (Gaussians) and physical (particles) aspects of the world and enables forward prediction of robot interactions with the world.
A photometric loss between rendered Gaussians and observed images is computed (Gaussian Splatting) and converted into visual forces. These and other physical phenomena such as gravity, collisions, and mechanical forces are resolved by the always-active physics system and applied to the particles, which in turn influence the position of their associated Gaussians.
[website]
Our dual Gaussian-Particle representation captures visual (Gaussians) and physical (particles) aspects of the world and enables forward prediction of robot interactions with the world.
A photometric loss between rendered Gaussians and observed images is computed (Gaussian Splatting) and converted into visual forces. These and other physical phenomena such as gravity, collisions, and mechanical forces are resolved by the always-active physics system and applied to the particles, which in turn influence the position of their associated Gaussians.
[website]
-
ParticleNeRF: Particle Based Encoding for Online Neural Radiance Fields in Dynamic Scenes In IEEE Winter Conference on Applications of Computer Vision (WACV), 2024. Best Paper Honourable Mention & Oral Presentation
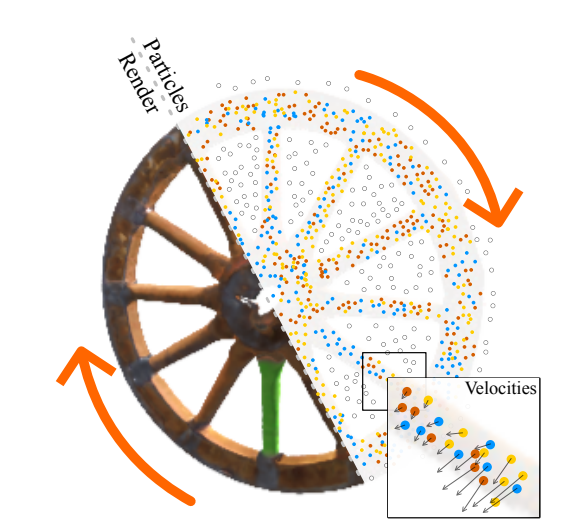 While existing Neural Radiance Fields (NeRFs) for dynamic scenes are offline methods with an emphasis on visual fidelity, our paper addresses the online use case that prioritises real-time adaptability. We present ParticleNeRF, a new approach that dynamically adapts to changes in the scene geometry by learning an up-to-date representation online, every 200ms. ParticleNeRF achieves this using a novel particle-based parametric encoding. We couple features to particles in space and backpropagate the photometric reconstruction loss into the particles’ position gradients, which are then interpreted as velocity vectors. Governed by a lightweight physics system to handle collisions, this lets the features move freely with the changing scene geometry.
[arXiv]
[website]
While existing Neural Radiance Fields (NeRFs) for dynamic scenes are offline methods with an emphasis on visual fidelity, our paper addresses the online use case that prioritises real-time adaptability. We present ParticleNeRF, a new approach that dynamically adapts to changes in the scene geometry by learning an up-to-date representation online, every 200ms. ParticleNeRF achieves this using a novel particle-based parametric encoding. We couple features to particles in space and backpropagate the photometric reconstruction loss into the particles’ position gradients, which are then interpreted as velocity vectors. Governed by a lightweight physics system to handle collisions, this lets the features move freely with the changing scene geometry.
[arXiv]
[website]
-
Density-aware NeRF Ensembles: Quantifying Predictive Uncertainty in Neural Radiance Fields In IEEE Conference on Robotics and Automation (ICRA), 2023.
 We show that ensembling effectively quantifies
model uncertainty in Neural Radiance Fields (NeRFs) if a
density-aware epistemic uncertainty term is considered. The
naive ensembles investigated in prior work simply average
rendered RGB images to quantify the model uncertainty caused
by conflicting explanations of the observed scene. In contrast,
we additionally consider the termination probabilities along
individual rays to identify epistemic model uncertainty due to
a lack of knowledge about the parts of a scene unobserved
during training. We achieve new state-of-the-art performance
across established uncertainty quantification benchmarks for
NeRFs, outperforming methods that require complex changes
to the NeRF architecture and training regime. We furthermore
demonstrate that NeRF uncertainty can be utilised for next-best
view selection and model refinement.
[arXiv]
We show that ensembling effectively quantifies
model uncertainty in Neural Radiance Fields (NeRFs) if a
density-aware epistemic uncertainty term is considered. The
naive ensembles investigated in prior work simply average
rendered RGB images to quantify the model uncertainty caused
by conflicting explanations of the observed scene. In contrast,
we additionally consider the termination probabilities along
individual rays to identify epistemic model uncertainty due to
a lack of knowledge about the parts of a scene unobserved
during training. We achieve new state-of-the-art performance
across established uncertainty quantification benchmarks for
NeRFs, outperforming methods that require complex changes
to the NeRF architecture and training regime. We furthermore
demonstrate that NeRF uncertainty can be utilised for next-best
view selection and model refinement.
[arXiv]
Semantic SLAM and Semantic Mapping
We work on novel approaches to SLAM (Simultaneous Localization and Mapping) that create semantically meaningful maps by combining geometric and semantic information.
We believe such semantically enriched maps will help robots understand our complex world and will ultimately increase the range and sophistication of interactions that robots can have in domestic and industrial deployment scenarios.
-
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation In IEEE Conference on Robotics and Automation (ICRA), 2024. Oral Presentation at ICRA, Oral Presentation at CoRL Workshop
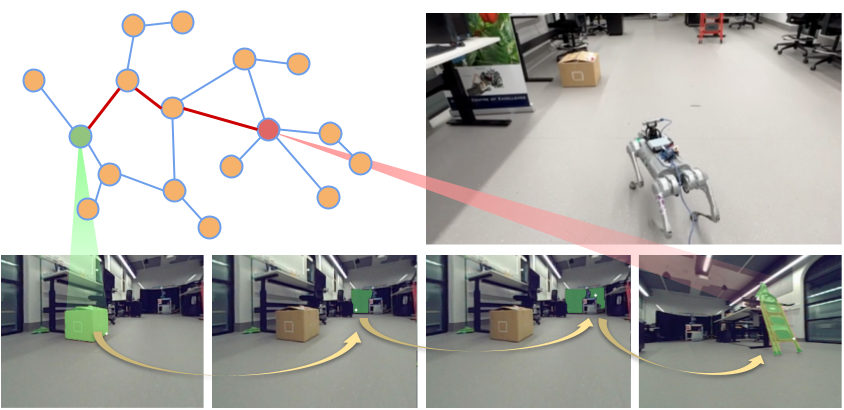 We propose a novel topological representation of an environment based on image segments, which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph but with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a continuous sense of a ‘place’, defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval.
[website]
We propose a novel topological representation of an environment based on image segments, which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph but with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a continuous sense of a ‘place’, defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval.
[website]
-
Retrospectives on the Embodied AI Workshop arXiv preprint arXiv:2210.06849, 2022.
 We present a retrospective on the state of Embodied AI
research. Our analysis focuses on 13 challenges presented
at the Embodied AI Workshop at CVPR. These challenges
are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We
discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of stateof-the-art models. We highlight commonalities between top
approaches to the challenges and identify potential future
directions for Embodied AI research.
[arXiv]
We present a retrospective on the state of Embodied AI
research. Our analysis focuses on 13 challenges presented
at the Embodied AI Workshop at CVPR. These challenges
are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We
discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of stateof-the-art models. We highlight commonalities between top
approaches to the challenges and identify potential future
directions for Embodied AI research.
[arXiv]
-
BenchBot environments for active robotics (BEAR): Simulated data for active scene understanding research The International Journal of Robotics Research, 2022.
 We present a platform to foster research in active scene understanding, consisting of high-fidelity simulated environments and a simple yet powerful API that controls a mobile robot in simulation and reality. In contrast to static, pre-recorded datasets that focus on the perception aspect of scene understanding, agency is a top priority in our work. We provide three levels of robot agency, allowing users to control a robot at varying levels of difficulty and realism. While the most basic level provides pre-defined trajectories and ground-truth localisation, the more realistic levels allow us to evaluate integrated behaviours comprising perception, navigation, exploration and SLAM.
[website]
We present a platform to foster research in active scene understanding, consisting of high-fidelity simulated environments and a simple yet powerful API that controls a mobile robot in simulation and reality. In contrast to static, pre-recorded datasets that focus on the perception aspect of scene understanding, agency is a top priority in our work. We provide three levels of robot agency, allowing users to control a robot at varying levels of difficulty and realism. While the most basic level provides pre-defined trajectories and ground-truth localisation, the more realistic levels allow us to evaluate integrated behaviours comprising perception, navigation, exploration and SLAM.
[website]
-
The Robotic Vision Scene Understanding Challenge arXiv preprint arXiv:2009.05246, 2020.
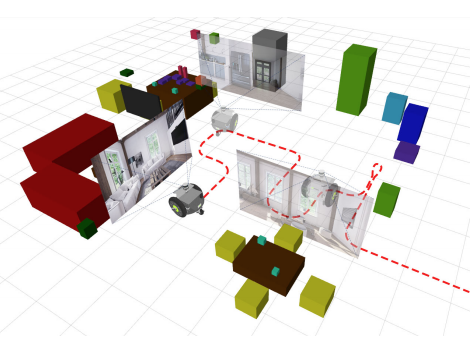 Being able to explore an environment and understand the location and type of all objects therein is important for indoor robotic platforms that must interact closely with humans. However, it is difficult to evaluate progress in this area due to a lack of standardized testing which is limited due to the need for active robot agency and perfect object ground-truth. To help provide a standard for testing scene understanding systems, we present a new robot vision scene understanding challenge using simulation to enable repeatable experiments with active robot agency. We provide two challenging task types, three difficulty levels, five simulated environments and a new evaluation measure for evaluating 3D cuboid object maps.
[arXiv]
[website]
Being able to explore an environment and understand the location and type of all objects therein is important for indoor robotic platforms that must interact closely with humans. However, it is difficult to evaluate progress in this area due to a lack of standardized testing which is limited due to the need for active robot agency and perfect object ground-truth. To help provide a standard for testing scene understanding systems, we present a new robot vision scene understanding challenge using simulation to enable repeatable experiments with active robot agency. We provide two challenging task types, three difficulty levels, five simulated environments and a new evaluation measure for evaluating 3D cuboid object maps.
[arXiv]
[website]
-
Benchbot: Evaluating robotics research in photorealistic 3d simulation and on real robots arXiv preprint arXiv:2008.00635, 2020.
 We introduce BenchBot, a novel software suite for benchmarking the performance of robotics research across both photorealistic 3D simulations and real robot platforms. BenchBot provides a simple interface to the sensorimotor capabilities of a robot when solving robotics research problems; an interface that is consistent regardless of whether the target platform is simulated or a real robot. In this paper we outline the BenchBot system architecture, and explore the parallels between its user-centric design and an ideal research development process devoid of tangential robot engineering challenges.
[arXiv]
[website]
We introduce BenchBot, a novel software suite for benchmarking the performance of robotics research across both photorealistic 3D simulations and real robot platforms. BenchBot provides a simple interface to the sensorimotor capabilities of a robot when solving robotics research problems; an interface that is consistent regardless of whether the target platform is simulated or a real robot. In this paper we outline the BenchBot system architecture, and explore the parallels between its user-centric design and an ideal research development process devoid of tangential robot engineering challenges.
[arXiv]
[website]
-
Evaluating the Impact of Semantic Segmentation and Pose Estimationon Dense Semantic SLAM In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2021.
 Recent Semantic SLAM methods combine classical geometry-based estimation with deep learning-based object detection or semantic segmentation.
In this paper we evaluate the quality of semantic maps generated by state-of-the-art class- and instance-aware dense semantic SLAM algorithms whose codes are publicly available and explore the impacts both semantic segmentation and pose estimation have on the quality of semantic maps.
We obtain these results by providing algorithms with ground-truth pose and/or semantic segmentation data available from simulated environments. We establish that semantic segmentation is the largest source of error through our experiments, dropping mAP and OMQ performance by up to 74.3% and 71.3% respectively.
Recent Semantic SLAM methods combine classical geometry-based estimation with deep learning-based object detection or semantic segmentation.
In this paper we evaluate the quality of semantic maps generated by state-of-the-art class- and instance-aware dense semantic SLAM algorithms whose codes are publicly available and explore the impacts both semantic segmentation and pose estimation have on the quality of semantic maps.
We obtain these results by providing algorithms with ground-truth pose and/or semantic segmentation data available from simulated environments. We establish that semantic segmentation is the largest source of error through our experiments, dropping mAP and OMQ performance by up to 74.3% and 71.3% respectively.
-
QuadricSLAM: Constrained Dual Quadrics from Object Detections as Landmarks in Object-oriented SLAM IEEE Robotics and Automation Letters (RA-L), 2018.
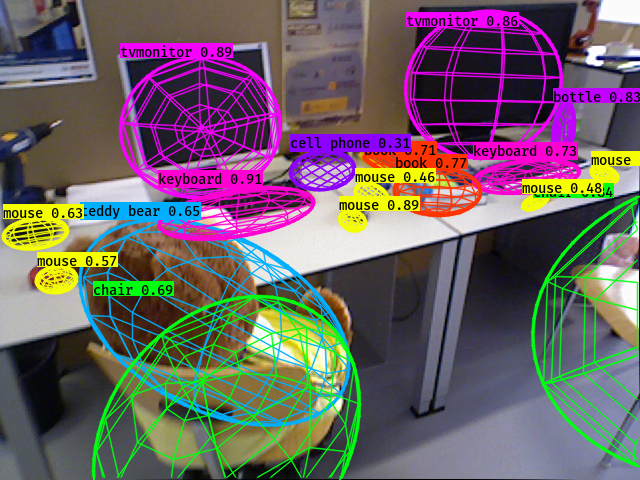 In this paper, we use 2D object detections from multiple views to simultaneously estimate a 3D quadric surface for each object and localize the camera position. We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D object detections can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for object detectors that addresses the challenge of partially visible objects, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
In this paper, we use 2D object detections from multiple views to simultaneously estimate a 3D quadric surface for each object and localize the camera position. We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D object detections can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for object detectors that addresses the challenge of partially visible objects, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
-
Structure Aware SLAM using Quadrics and Planes In Proceedings of Asian Conference on Computer Vision (ACCV), 2018. [arXiv]
-
An Orientation Factor for Object-Oriented SLAM arXiv preprint, 2018.
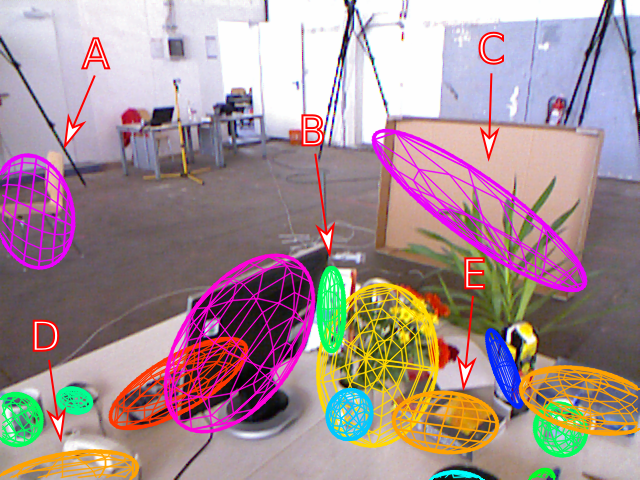 Current approaches to object-oriented SLAM lack the ability to incorporate prior knowledge of the scene geometry, such as the expected global orientation of objects. We overcome this limitation by proposing a geometric factor that constrains the global orientation of objects in the map, depending on the objects’ semantics. This new geometric factor is a first example of how semantics can inform and improve geometry in object-oriented SLAM. We implement the geometric factor for the recently proposed QuadricSLAM that represents landmarks as dual quadrics. The factor probabilistically models the quadrics’ major axes to be either perpendicular to or aligned with the direction of gravity, depending on their semantic class. Our experiments on simulated and real-world datasets show that using the proposed factors to incorporate prior knowledge improves both the trajectory and landmark quality.
[arXiv]
[website]
Current approaches to object-oriented SLAM lack the ability to incorporate prior knowledge of the scene geometry, such as the expected global orientation of objects. We overcome this limitation by proposing a geometric factor that constrains the global orientation of objects in the map, depending on the objects’ semantics. This new geometric factor is a first example of how semantics can inform and improve geometry in object-oriented SLAM. We implement the geometric factor for the recently proposed QuadricSLAM that represents landmarks as dual quadrics. The factor probabilistically models the quadrics’ major axes to be either perpendicular to or aligned with the direction of gravity, depending on their semantic class. Our experiments on simulated and real-world datasets show that using the proposed factors to incorporate prior knowledge improves both the trajectory and landmark quality.
[arXiv]
[website]
-
QuadricSLAM: Constrained Dual Quadrics from Object Detections as Landmarks in Semantic SLAM In Workshop on Representing a Complex World, International Conference on Robotics and Automation (ICRA), 2018. Best Workshop Paper Award
 We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D bounding boxes (such as those typically obtained from visual object detection systems) can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for deep-learned object detectors that addresses the challenge of partial object detections often encountered in robotics applications, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
We derive a SLAM formulation that uses dual quadrics as 3D landmark representations, exploiting their ability to compactly represent the size, position and orientation of an object, and show how 2D bounding boxes (such as those typically obtained from visual object detection systems) can directly constrain the quadric parameters via a novel geometric error formulation. We develop a sensor model for deep-learned object detectors that addresses the challenge of partial object detections often encountered in robotics applications, and demonstrate how to jointly estimate the camera pose and constrained dual quadric parameters in factor graph based SLAM with a general perspective camera.
[arXiv]
[website]
-
Meaningful Maps With Object-Oriented Semantic Mapping In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2017.
 For intelligent robots to interact in meaningful ways with their environment, they must understand both the geometric and semantic properties of the scene surrounding them. The majority of research to date has addressed these mapping challenges separately, focusing on either geometric or semantic mapping. In this paper we address the problem of building environmental maps that include both semantically meaningful, object-level entities and point- or mesh-based geometrical representations. We simultaneously build geometric point cloud models of previously unseen instances of known object classes and create a map that contains these object models as central entities. Our system leverages sparse, feature-based RGB-D SLAM, image-based deep-learning object detection and 3D unsupervised segmentation.
For intelligent robots to interact in meaningful ways with their environment, they must understand both the geometric and semantic properties of the scene surrounding them. The majority of research to date has addressed these mapping challenges separately, focusing on either geometric or semantic mapping. In this paper we address the problem of building environmental maps that include both semantically meaningful, object-level entities and point- or mesh-based geometrical representations. We simultaneously build geometric point cloud models of previously unseen instances of known object classes and create a map that contains these object models as central entities. Our system leverages sparse, feature-based RGB-D SLAM, image-based deep-learning object detection and 3D unsupervised segmentation.
-
Place Categorization and Semantic Mapping on a Mobile Robot Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2016.
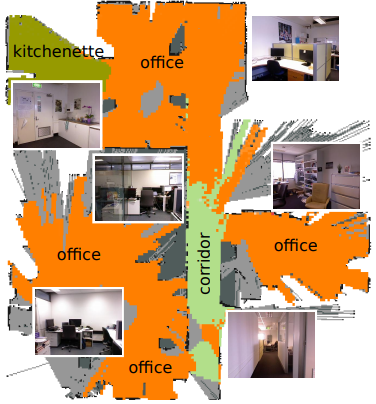 In this paper we focus on the challenging problem of place categorization and semantic mapping on a robot without environment-specific training. Motivated by their ongoing success in various visual recognition tasks, we build our system upon a state-of-the-art convolutional network. We overcome its closed-set limitations by complementing the network with a series of one-vs-all classifiers that can learn to recognize new semantic classes online. Prior domain knowledge is incorporated by embedding the classification system into a Bayesian filter framework that also ensures temporal coherence. We evaluate the classification accuracy of the system on a robot that maps a variety of places on our campus in real-time. We show how semantic information can boost robotic object detection performance and how the semantic map can be used to modulate the robot’s behaviour during navigation tasks. The system is made available to the community as a ROS module.
In this paper we focus on the challenging problem of place categorization and semantic mapping on a robot without environment-specific training. Motivated by their ongoing success in various visual recognition tasks, we build our system upon a state-of-the-art convolutional network. We overcome its closed-set limitations by complementing the network with a series of one-vs-all classifiers that can learn to recognize new semantic classes online. Prior domain knowledge is incorporated by embedding the classification system into a Bayesian filter framework that also ensures temporal coherence. We evaluate the classification accuracy of the system on a robot that maps a variety of places on our campus in real-time. We show how semantic information can boost robotic object detection performance and how the semantic map can be used to modulate the robot’s behaviour during navigation tasks. The system is made available to the community as a ROS module.
-
SLAM – Quo Vadis? In Support of Object Oriented and Semantic SLAM In Workshop on The Problem of Moving Sensors, Robotics: Science and Systems (RSS), 2015.
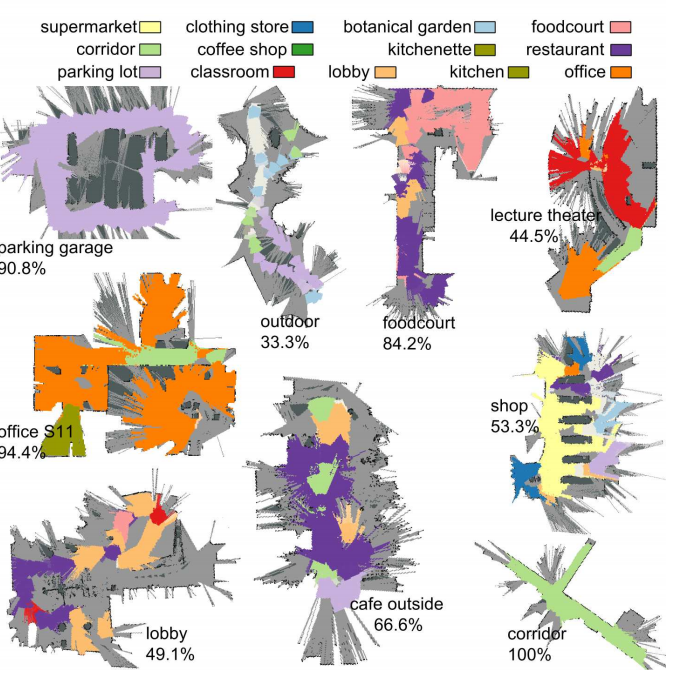 Most current SLAM systems are still based on
primitive geometric features such as points, lines, or planes.
The created maps therefore carry geometric information, but
no immediate semantic information. With the recent significant
advances in object detection and scene classification we think the
time is right for the SLAM community to ask where the SLAM
research should be going during the next years. As a possible
answer to this question, we advocate developing SLAM systems
that are more object oriented and more semantically enriched
than the current state of the art. This paper provides an overview
of our ongoing work in this direction.
Most current SLAM systems are still based on
primitive geometric features such as points, lines, or planes.
The created maps therefore carry geometric information, but
no immediate semantic information. With the recent significant
advances in object detection and scene classification we think the
time is right for the SLAM community to ask where the SLAM
research should be going during the next years. As a possible
answer to this question, we advocate developing SLAM systems
that are more object oriented and more semantically enriched
than the current state of the art. This paper provides an overview
of our ongoing work in this direction.
Scene Understanding
-
SceneCut: Joint Geometric and Object Segmentation for Indoor Scenes In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2018.
 This paper presents SceneCut, a novel approach to jointly discover previously unseen
objects and non-object surfaces using a single RGB-D image. SceneCut’s joint reasoning
over scene semantics and geometry allows a robot to detect and segment object instances
in complex scenes where modern deep learning-based methods either fail to separate
object instances, or fail to detect objects that were not seen during training. SceneCut
automatically decomposes a scene into meaningful regions which either represent objects
or scene surfaces. The decomposition is qualified by an unified energy function over
objectness and geometric fitting. We show how this energy function can be optimized
efficiently by utilizing hierarchical segmentation trees.
This paper presents SceneCut, a novel approach to jointly discover previously unseen
objects and non-object surfaces using a single RGB-D image. SceneCut’s joint reasoning
over scene semantics and geometry allows a robot to detect and segment object instances
in complex scenes where modern deep learning-based methods either fail to separate
object instances, or fail to detect objects that were not seen during training. SceneCut
automatically decomposes a scene into meaningful regions which either represent objects
or scene surfaces. The decomposition is qualified by an unified energy function over
objectness and geometric fitting. We show how this energy function can be optimized
efficiently by utilizing hierarchical segmentation trees.
-
Enhancing Human Action Recognition with Region Proposals In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2015.
-
Continuous Factor Graphs For Holistic Scene Understanding In Workshop on Scene Understanding (SUNw), Intl. Conf. on Computer Vision and Pattern Recognition (CVPR), 2015.
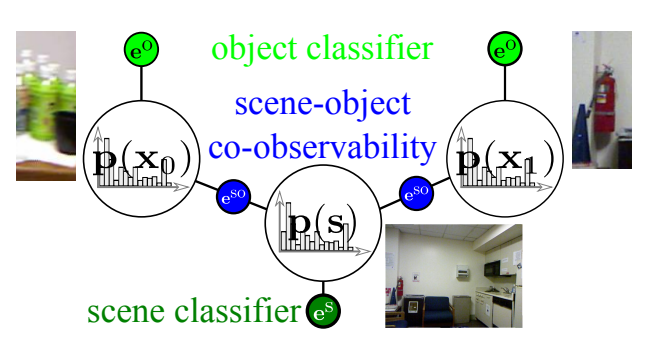 We propose a novel mathematical formulation for the
holistic scene understanding problem and transform it from
the discrete into the continuous domain. The problem can
then be modeled with a nonlinear continuous factor graph,
and the MAP solution is found via least squares optimization.
We evaluate our method on the realistic NYU2 dataset.
We propose a novel mathematical formulation for the
holistic scene understanding problem and transform it from
the discrete into the continuous domain. The problem can
then be modeled with a nonlinear continuous factor graph,
and the MAP solution is found via least squares optimization.
We evaluate our method on the realistic NYU2 dataset.
Scene Understanding: Hazard Detection
-
Multi-Modal Trip Hazard Affordance Detection On Construction Sites IEEE Robotics and Automation Letters (RA-L), 2017.
 Trip hazards are a significant contributor to accidents on construction and manufacturing sites. We conduct a comprehensive investigation into the performance characteristics of 11 different colors and depth fusion approaches, including four fusion and one nonfusion approach, using color and two types of depth images. Trained and tested on more than 600 labeled trip hazards over four floors and 2000 m2 in an active construction site, this approach was able to differentiate between identical objects in different physical configurations. Outperforming a color-only detector, our multimodal trip detector fuses color and depth information to achieve a 4% absolute improvement in F1-score. These investigative results and the extensive publicly available dataset move us one step closer to assistive or fully automated safety inspection systems on construction sites.
Trip hazards are a significant contributor to accidents on construction and manufacturing sites. We conduct a comprehensive investigation into the performance characteristics of 11 different colors and depth fusion approaches, including four fusion and one nonfusion approach, using color and two types of depth images. Trained and tested on more than 600 labeled trip hazards over four floors and 2000 m2 in an active construction site, this approach was able to differentiate between identical objects in different physical configurations. Outperforming a color-only detector, our multimodal trip detector fuses color and depth information to achieve a 4% absolute improvement in F1-score. These investigative results and the extensive publicly available dataset move us one step closer to assistive or fully automated safety inspection systems on construction sites.
-
Auxiliary Tasks to Improve Trip Hazard Affordance Detection In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2017.
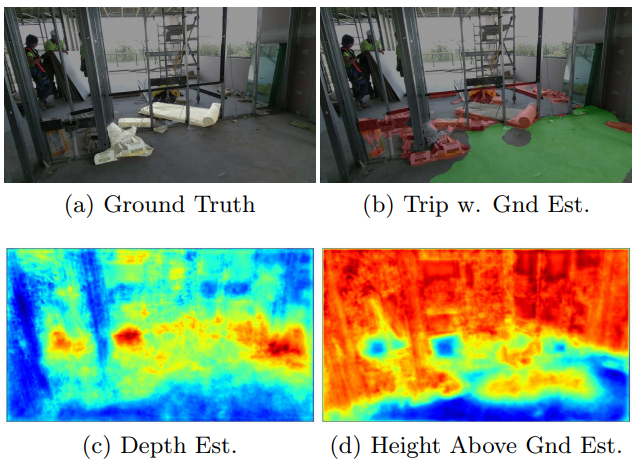 We propose to train a CNN performing pixel-wise trip detection with three auxiliary tasks to help the CNN better infer scene geometric properties of trip hazards. Of the three approaches investigated pixel-wise ground plane estimation, pixel depth estimation and pixel height above ground plane estimation, the first approach allowed the trip detector to achieve a 11.1% increase in Trip IOU over earlier work. These new approaches make it plausible to deploy a robotic platform to perform trip hazard detection, and so potentially reduce the number of injuries on construction sites.
We propose to train a CNN performing pixel-wise trip detection with three auxiliary tasks to help the CNN better infer scene geometric properties of trip hazards. Of the three approaches investigated pixel-wise ground plane estimation, pixel depth estimation and pixel height above ground plane estimation, the first approach allowed the trip detector to achieve a 11.1% increase in Trip IOU over earlier work. These new approaches make it plausible to deploy a robotic platform to perform trip hazard detection, and so potentially reduce the number of injuries on construction sites.
-
TripNet: Detecting Trip Hazards on Construction Sites In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2015.
 This paper introduces TripNet, a robotic vision system that detects trip hazards using raw construction site images.
TripNet performs trip hazard identification using only camera imagery and minimal training with a pre-trained Convolutional Neural Network (CNN) rapidly fine-tuned on a small corpus of labelled image regions from construction sites. There is no reliance on prior scene segmentation methods during deployment. Trip-Net achieves comparable performance to a human on a dataset recorded in two distinct real world construction sites. TripNet exhibits spatial and temporal generalization by functioning in previously unseen parts of a construction site and over time periods of several weeks.
This paper introduces TripNet, a robotic vision system that detects trip hazards using raw construction site images.
TripNet performs trip hazard identification using only camera imagery and minimal training with a pre-trained Convolutional Neural Network (CNN) rapidly fine-tuned on a small corpus of labelled image regions from construction sites. There is no reliance on prior scene segmentation methods during deployment. Trip-Net achieves comparable performance to a human on a dataset recorded in two distinct real world construction sites. TripNet exhibits spatial and temporal generalization by functioning in previously unseen parts of a construction site and over time periods of several weeks.