Robot Learning

How can robots learn everyday tasks such as tidying up an apartment or assisting humans in their everyday domestic chores?
With a fantastic team, I am interested in robotic learning for Manipulation, Complex Task Planning, and Navigation.
We combine modern techniques such as imitation learning, LLMs, Vision-Language Models, and reinforcement learning with classical control and navigation, but also with a fresh take on representing the environment with NeRFs or Gaussian Splatting.
Join us for your PhD or Postdoc!
I am hiring a Postdoc in Robot Learning starting immediately (from September 2025). Please check here if you are interested.
If you want to do a PhD with us in this area, read more information here.
Publications
-
Learning from 10 Demos: Generalisable and Sample-Efficient Policy Learning with Oriented Affordance Frames In Conference on Robot Learning (CoRL), 2025.
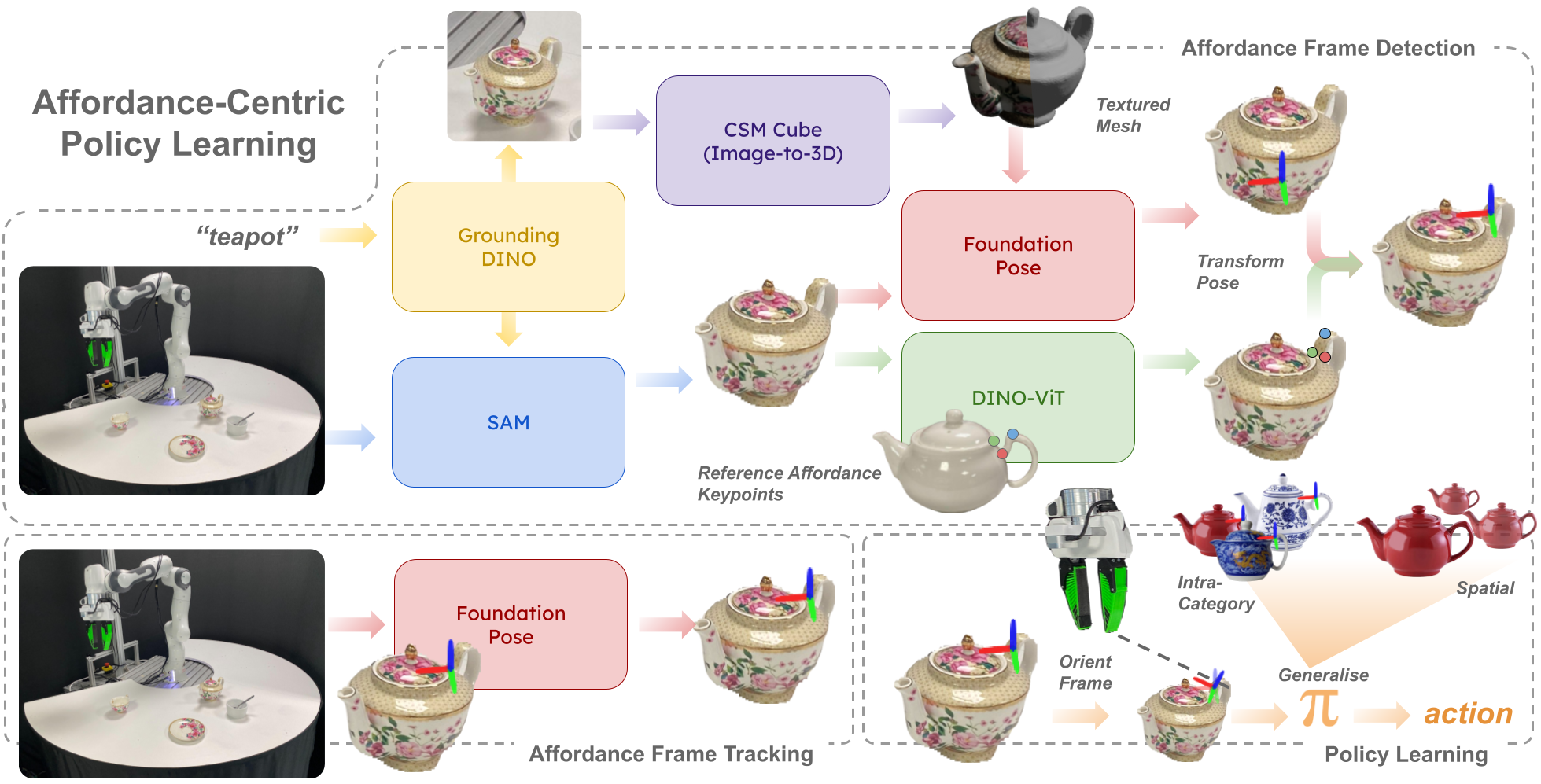 We introduce oriented affordance frames, a structured representation for state and action spaces that improves spatial and intra-category generalisation and enables policies to be learned efficiently from only 10 demonstrations. More importantly, we show how this abstraction allows for compositional generalisation of independently trained sub-policies to solve long-horizon, multi-object tasks. To seamlessly transition between sub-policies, we introduce the notion of self-progress prediction, which we directly derive from the duration of the training demonstrations. We validate our method across three real-world tasks, each requiring multi-step, multi-object interactions. Despite the small dataset, our policies generalise robustly to unseen object appearances, geometries, and spatial arrangements, achieving high success rates without reliance on exhaustive training data.
[arXiv]
[website]
We introduce oriented affordance frames, a structured representation for state and action spaces that improves spatial and intra-category generalisation and enables policies to be learned efficiently from only 10 demonstrations. More importantly, we show how this abstraction allows for compositional generalisation of independently trained sub-policies to solve long-horizon, multi-object tasks. To seamlessly transition between sub-policies, we introduce the notion of self-progress prediction, which we directly derive from the duration of the training demonstrations. We validate our method across three real-world tasks, each requiring multi-step, multi-object interactions. Despite the small dataset, our policies generalise robustly to unseen object appearances, geometries, and spatial arrangements, achieving high success rates without reliance on exhaustive training data.
[arXiv]
[website]
-
Real-is-Sim: Bridging the Sim-to-Real Gap with a Dynamic Digital Twin for Real-World Robot Policy Evaluation arXiv preprint arXiv:2504.03597, 2025.
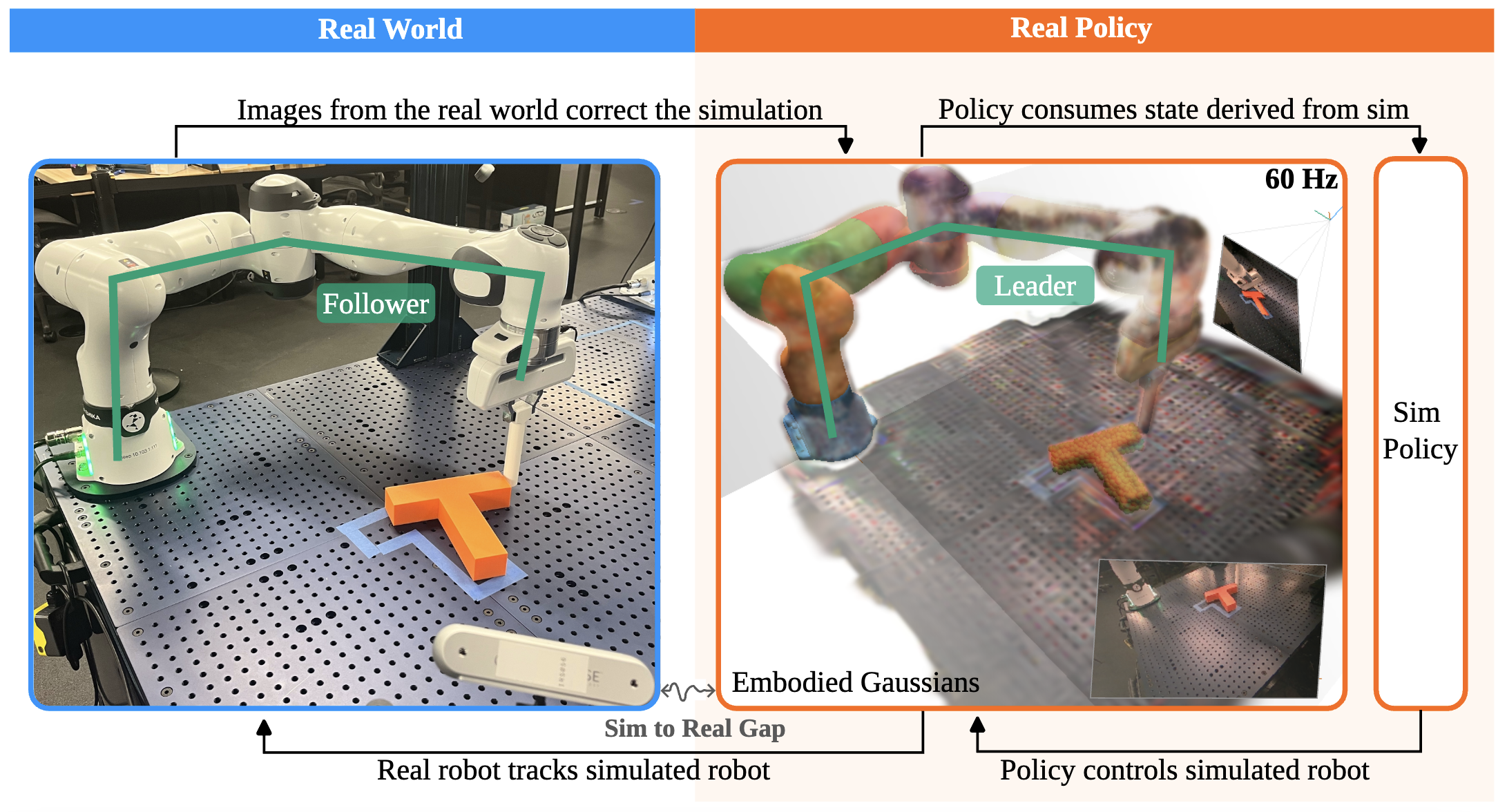 We introduce real-is-sim, a new approach to integrating simulation into behavior cloning pipelines. In contrast to real-only methods, which lack the ability to safely test policies before deployment, and sim-to-real methods, which require complex adaptation to cross the sim-to-real gap, our framework allows policies to seamlessly switch between running on real hardware and running in parallelized virtual environments. At the center of real-is-sim is a dynamic digital twin, powered by the Embodied Gaussian simulator, that synchronizes with the real world at 60Hz. This twin acts as a mediator between the behavior cloning policy and the real robot. Policies are trained using representations derived from simulator states and always act on the simulated robot, never the real one. During deployment, the real robot simply follows the simulated robot’s joint states, and the simulation is continuously corrected with real world measurements. This setup, where the simulator drives all policy execution and maintains real-time synchronization with the physical world, shifts the responsibility of crossing the sim-to-real gap to the digital twin’s synchronization mechanisms, instead of the policy itself.
[arXiv]
[website]
We introduce real-is-sim, a new approach to integrating simulation into behavior cloning pipelines. In contrast to real-only methods, which lack the ability to safely test policies before deployment, and sim-to-real methods, which require complex adaptation to cross the sim-to-real gap, our framework allows policies to seamlessly switch between running on real hardware and running in parallelized virtual environments. At the center of real-is-sim is a dynamic digital twin, powered by the Embodied Gaussian simulator, that synchronizes with the real world at 60Hz. This twin acts as a mediator between the behavior cloning policy and the real robot. Policies are trained using representations derived from simulator states and always act on the simulated robot, never the real one. During deployment, the real robot simply follows the simulated robot’s joint states, and the simulation is continuously corrected with real world measurements. This setup, where the simulator drives all policy execution and maintains real-time synchronization with the physical world, shifts the responsibility of crossing the sim-to-real gap to the digital twin’s synchronization mechanisms, instead of the policy itself.
[arXiv]
[website]
-
IMLE Policy: Fast and Sample Efficient Visuomotor Policy Learning via Implicit Maximum Likelihood Estimation In Robotics: Science and Systems (RSS), 2025.
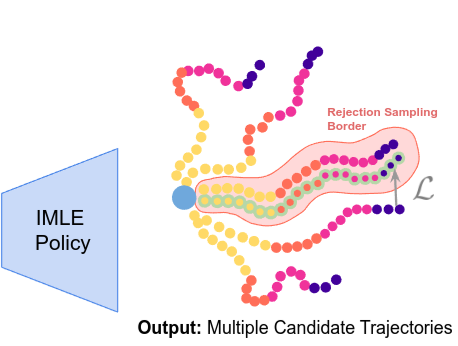 We introduce IMLE Policy, a novel behaviour cloning approach based on Implicit Maximum Likelihood Estimation (IMLE). IMLE Policy excels in low-data regimes, effectively learning from minimal demonstrations and requiring 38% less data on average to match the performance of baseline methods in learning complex multi-modal behaviours. Its simple generator-based architecture enables single-step action generation, improving inference speed by 97.3% compared to Diffusion Policy, while outperforming single-step Flow Matching.
[arXiv]
[website]
We introduce IMLE Policy, a novel behaviour cloning approach based on Implicit Maximum Likelihood Estimation (IMLE). IMLE Policy excels in low-data regimes, effectively learning from minimal demonstrations and requiring 38% less data on average to match the performance of baseline methods in learning complex multi-modal behaviours. Its simple generator-based architecture enables single-step action generation, improving inference speed by 97.3% compared to Diffusion Policy, while outperforming single-step Flow Matching.
[arXiv]
[website]
-
Physically Embodied Gaussian Splatting: A Realtime Correctable World Model for Robotics In Conference on Robot Learning (CoRL), 2024. Oral Presentation
 We propose a novel dual "Gaussian-Particle" representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates "visual forces" that correct the particle positions while respecting known physical constraints. By integrating predictive physical modeling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality.
[arXiv]
[website]
We propose a novel dual "Gaussian-Particle" representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates "visual forces" that correct the particle positions while respecting known physical constraints. By integrating predictive physical modeling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality.
[arXiv]
[website]
-
Open X-Embodiment: Robotic Learning Datasets and RT-X Models In IEEE Conference on Robotics and Automation (ICRA), 2024. ICRA Best Conference Paper. ICRA Best Paper Award in Robot Manipulation.
 Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms.
[arXiv]
[website]
Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms.
[arXiv]
[website]
-
Sayplan: Grounding Large Language Models Using 3d Scene Graphs for Scalable Robot Task Planning In Conference on Robot Learning (CoRL), 2023. Oral Presentation
 We introduce SayPlan, a scalable approach to LLM-based,
large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical
nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant
subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the
planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback
from a scene graph simulator, correcting infeasible actions and avoiding planning
failures. We evaluate our approach on two large-scale environments spanning up
to 3 floors and 36 rooms with 140 assets and objects and show that our approach is
capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute.
[arXiv]
[website]
We introduce SayPlan, a scalable approach to LLM-based,
large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical
nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant
subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the
planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback
from a scene graph simulator, correcting infeasible actions and avoiding planning
failures. We evaluate our approach on two large-scale environments spanning up
to 3 floors and 36 rooms with 140 assets and objects and show that our approach is
capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute.
[arXiv]
[website]
-
LHManip: A Dataset for Long-Horizon Language-Grounded Manipulation Tasks in Cluttered Tabletop Environments arXiv preprint arXiv:2312.12036, 2023.
 We present the Long-Horizon Manipulation (LHManip) dataset comprising 200
episodes, demonstrating 20 different manipulation tasks via real robot teleoperation. The tasks entail multiple sub-tasks,
including grasping, pushing, stacking and throwing objects in highly cluttered environments. Each task is paired with a
natural language instruction and multi-camera viewpoints for point-cloud or NeRF reconstruction. In total, the dataset
comprises 176,278 observation-action pairs which form part of the Open X-Embodiment dataset.
[arXiv]
[website]
We present the Long-Horizon Manipulation (LHManip) dataset comprising 200
episodes, demonstrating 20 different manipulation tasks via real robot teleoperation. The tasks entail multiple sub-tasks,
including grasping, pushing, stacking and throwing objects in highly cluttered environments. Each task is paired with a
natural language instruction and multi-camera viewpoints for point-cloud or NeRF reconstruction. In total, the dataset
comprises 176,278 observation-action pairs which form part of the Open X-Embodiment dataset.
[arXiv]
[website]
-
Contrastive Language, Action, and State Pre-training for Robot Learning In ICRA Workshop on Pretraining for Robotics (PT4R), 2023.
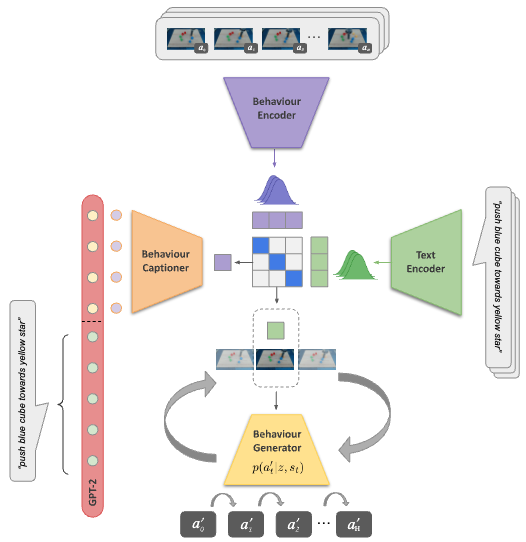 We introduce a method for unifying language, action, and state information in a shared embedding space to facilitate a range of downstream tasks in robot learning. Our method, Contrastive Language, Action, and State Pre-training (CLASP), extends the CLIP formulation by incorporating distributional learning, capturing the inherent complexities and one-to-many relationships in behaviour-text alignment. By employing distributional outputs for both text and behaviour encoders, our model effectively associates diverse textual commands with a single behaviour and vice-versa. We demonstrate the utility of our method for the following downstream tasks: zero-shot text-behaviour retrieval, captioning unseen robot behaviours, and learning a behaviour prior for language-conditioned reinforcement learning.
[arXiv]
We introduce a method for unifying language, action, and state information in a shared embedding space to facilitate a range of downstream tasks in robot learning. Our method, Contrastive Language, Action, and State Pre-training (CLASP), extends the CLIP formulation by incorporating distributional learning, capturing the inherent complexities and one-to-many relationships in behaviour-text alignment. By employing distributional outputs for both text and behaviour encoders, our model effectively associates diverse textual commands with a single behaviour and vice-versa. We demonstrate the utility of our method for the following downstream tasks: zero-shot text-behaviour retrieval, captioning unseen robot behaviours, and learning a behaviour prior for language-conditioned reinforcement learning.
[arXiv]
-
Bayesian Controller Fusion: Leveraging Control Priors in Deep Reinforcement Learning for Robotics The International Journal of Robotics Research (IJRR), 2023.
 We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths.
As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience.
More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy.
We additionally show BCF’s applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real-world.
BCF is a promising approach for combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently.
[arXiv]
[website]
We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths.
As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience.
More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy.
We additionally show BCF’s applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real-world.
BCF is a promising approach for combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently.
[arXiv]
[website]
-
Residual Skill Policies: Learning an Adaptable Skill-based Action Space for Reinforcement Learning for Robotics In Conference on Robot Learning (CoRL), 2022.
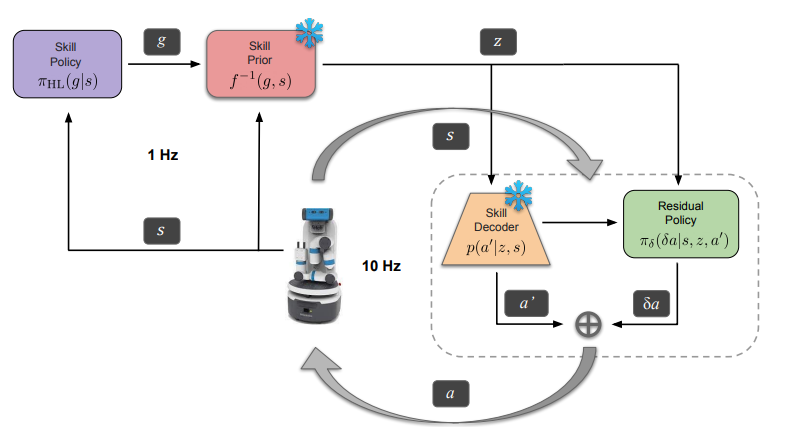 Skill-based reinforcement learning (RL) has emerged as a promising strategy to
leverage prior knowledge for accelerated robot learning. We firstly
propose accelerating exploration in the skill space using state-conditioned generative models to directly bias the high-level agent towards only sampling skills
relevant to a given state based on prior experience. Next, we propose a low-level
residual policy for fine-grained skill adaptation enabling downstream RL agents
to adapt to unseen task variations. Finally, we validate our approach across four
challenging manipulation tasks that differ from those used to build the skill space,
demonstrating our ability to learn across task variations while significantly accelerating exploration, outperforming prior works.
[arXiv]
[website]
Skill-based reinforcement learning (RL) has emerged as a promising strategy to
leverage prior knowledge for accelerated robot learning. We firstly
propose accelerating exploration in the skill space using state-conditioned generative models to directly bias the high-level agent towards only sampling skills
relevant to a given state based on prior experience. Next, we propose a low-level
residual policy for fine-grained skill adaptation enabling downstream RL agents
to adapt to unseen task variations. Finally, we validate our approach across four
challenging manipulation tasks that differ from those used to build the skill space,
demonstrating our ability to learn across task variations while significantly accelerating exploration, outperforming prior works.
[arXiv]
[website]
-
Zero-Shot Uncertainty-Aware Deployment of Simulation Trained Policies on Real-World Robots In NeuIPS Workshop on Deployable Decision Makig in Embodied Systems, 2021.
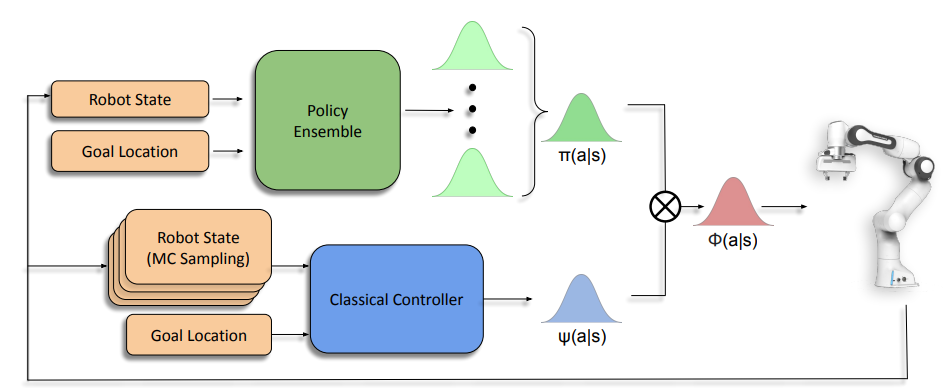 While deep reinforcement learning (RL) agents have demonstrated incredible potential in attaining dexterous behaviours for robotics, they tend to make errors when deployed in the real world due to mismatches between the training and execution environments. In contrast, the classical robotics community have developed a range of controllers that can safely operate across most states in the real world given their explicit derivation. These controllers however lack the dexterity required for complex tasks given limitations in analytical modelling and approximations. In this paper, we propose Bayesian Controller Fusion (BCF), a novel uncertainty-aware deployment strategy that combines the strengths of deep RL policies and traditional handcrafted controllers.
[arXiv]
While deep reinforcement learning (RL) agents have demonstrated incredible potential in attaining dexterous behaviours for robotics, they tend to make errors when deployed in the real world due to mismatches between the training and execution environments. In contrast, the classical robotics community have developed a range of controllers that can safely operate across most states in the real world given their explicit derivation. These controllers however lack the dexterity required for complex tasks given limitations in analytical modelling and approximations. In this paper, we propose Bayesian Controller Fusion (BCF), a novel uncertainty-aware deployment strategy that combines the strengths of deep RL policies and traditional handcrafted controllers.
[arXiv]
-
Multiplicative Controller Fusion: Leveraging Algorithmic Priors for Sample-efficient Reinforcement Learning and Safe Sim-To-Real Transfer In Proc. of IEEE International Conference on Intelligent Robots and Systems (IROS), 2020.
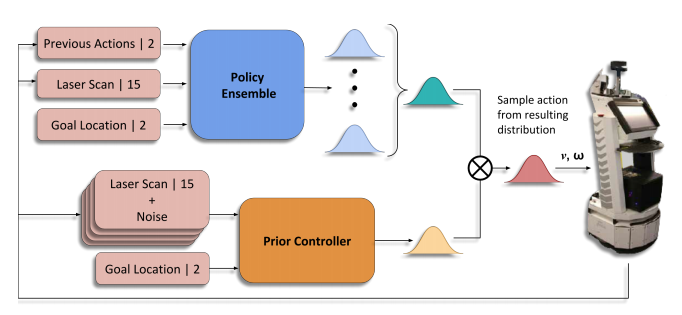 Learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior’s influence is annealed gradually. During deployment, the policy’s uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning.
[arXiv]
[website]
Learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior’s influence is annealed gradually. During deployment, the policy’s uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning.
[arXiv]
[website]
-
Residual Reactive Navigation: Combining Classical and Learned Navigation Strategies For Deployment in Unknown Environments In Proc. of IEEE International Conference on Robotics and Automation (ICRA), 2020.
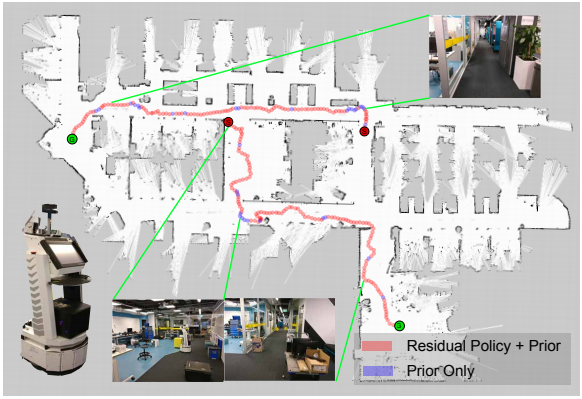 In this work we focus on improving the efficiency and generalisation of learned navigation strategies when transferred from its training environment to previously unseen ones. We present an extension of the residual reinforcement learning framework from the robotic manipulation literature and adapt it to the vast and unstructured environments that mobile robots can operate in. The concept is based on learning a residual control effect to add to a typical sub-optimal classical controller in order to close the performance gap, whilst guiding the exploration process during training for improved data efficiency. We exploit this tight coupling and propose a novel deployment strategy, switching Residual Reactive Navigation (sRNN), which yields efficient trajectories whilst probabilistically switching to a classical controller in cases of high policy uncertainty. Our approach achieves improved performance over end-to-end alternatives and can be incorporated as part of a complete navigation stack for cluttered indoor navigation tasks in the real world.
[arXiv]
[website]
In this work we focus on improving the efficiency and generalisation of learned navigation strategies when transferred from its training environment to previously unseen ones. We present an extension of the residual reinforcement learning framework from the robotic manipulation literature and adapt it to the vast and unstructured environments that mobile robots can operate in. The concept is based on learning a residual control effect to add to a typical sub-optimal classical controller in order to close the performance gap, whilst guiding the exploration process during training for improved data efficiency. We exploit this tight coupling and propose a novel deployment strategy, switching Residual Reactive Navigation (sRNN), which yields efficient trajectories whilst probabilistically switching to a classical controller in cases of high policy uncertainty. Our approach achieves improved performance over end-to-end alternatives and can be incorporated as part of a complete navigation stack for cluttered indoor navigation tasks in the real world.
[arXiv]
[website]
-
Where are the Keys? – Learning Object-Centric Navigation Policies on Semantic Maps with Graph Convolutional Networks arXiv preprint arXiv:1909.07376, 2019.
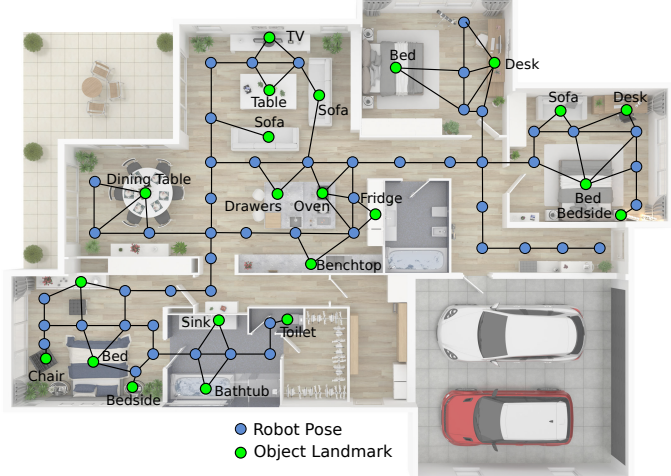 Emerging object-based SLAM algorithms can build a graph representation of an environment comprising nodes for robot poses and object landmarks. However, while this map will contain static objects such as furniture or appliances, many moveable objects (e.g. the car keys, the glasses, or a magazine), are not suitable as landmarks and will not be part of the map due to their non-static nature. We show that Graph Convolutional Networks can learn navigation policies to find such unmapped objects by learning to exploit the hidden probabilistic model that governs where these objects appear in the environment. The learned policies can generalise to object classes unseen during training by using word vectors that express semantic similarity as representations for object nodes in the graph. Furthermore, we show that the policies generalise to unseen environments with only minimal loss of performance. We demonstrate that pre-training the policy network with a proxy task can significantly speed up learning, improving sample efficiency.
[arXiv]
Emerging object-based SLAM algorithms can build a graph representation of an environment comprising nodes for robot poses and object landmarks. However, while this map will contain static objects such as furniture or appliances, many moveable objects (e.g. the car keys, the glasses, or a magazine), are not suitable as landmarks and will not be part of the map due to their non-static nature. We show that Graph Convolutional Networks can learn navigation policies to find such unmapped objects by learning to exploit the hidden probabilistic model that governs where these objects appear in the environment. The learned policies can generalise to object classes unseen during training by using word vectors that express semantic similarity as representations for object nodes in the graph. Furthermore, we show that the policies generalise to unseen environments with only minimal loss of performance. We demonstrate that pre-training the policy network with a proxy task can significantly speed up learning, improving sample efficiency.
[arXiv]
-
Sim-to-Real Transfer of Robot Learning with Variable Length Inputs In Australasian Conf. for Robotics and Automation (ACRA), 2019.
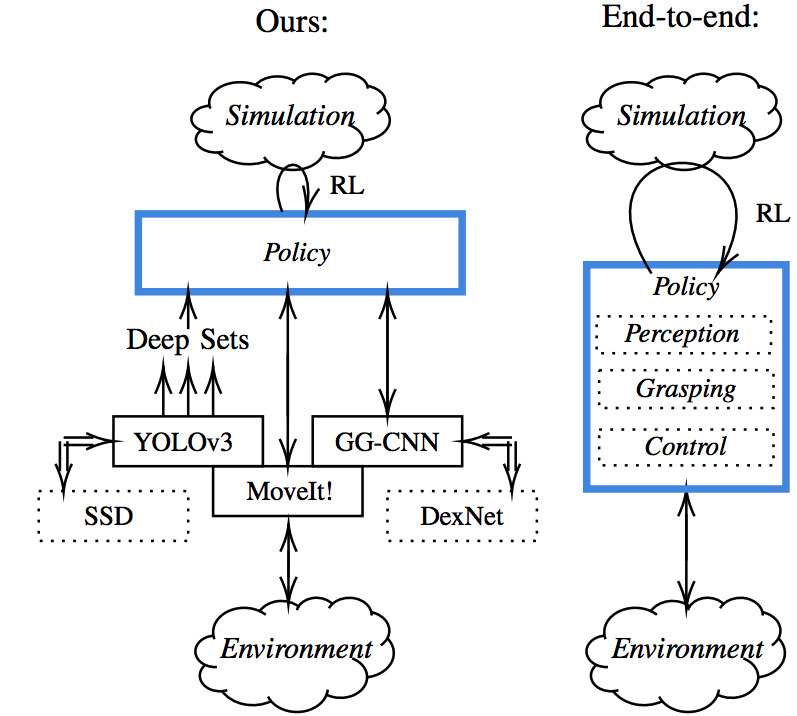 Current end-to-end deep Reinforcement Learning (RL) approaches require jointly learning perception, decision-making and low-level control from very sparse reward signals and high-dimensional inputs, with little capability of incorporating prior knowledge. In this work, we propose a framework that combines deep sets encoding, which allows for variable-length abstract representations, with modular RL that utilizes these representations, decoupling high-level decision making from low-level control. We successfully demonstrate our approach on the robot manipulation task of object sorting, showing that this method can learn effective policies within mere minutes of highly simplified simulation. The learned policies can be directly deployed on a robot without further training, and generalize to variations of the task unseen during training.
[arXiv]
Current end-to-end deep Reinforcement Learning (RL) approaches require jointly learning perception, decision-making and low-level control from very sparse reward signals and high-dimensional inputs, with little capability of incorporating prior knowledge. In this work, we propose a framework that combines deep sets encoding, which allows for variable-length abstract representations, with modular RL that utilizes these representations, decoupling high-level decision making from low-level control. We successfully demonstrate our approach on the robot manipulation task of object sorting, showing that this method can learn effective policies within mere minutes of highly simplified simulation. The learned policies can be directly deployed on a robot without further training, and generalize to variations of the task unseen during training.
[arXiv]
-
Learning Deployable Navigation Policies at Kilometer Scale from a Single Traversal In Proc. of Conference on Robot Learning (CoRL), 2018.
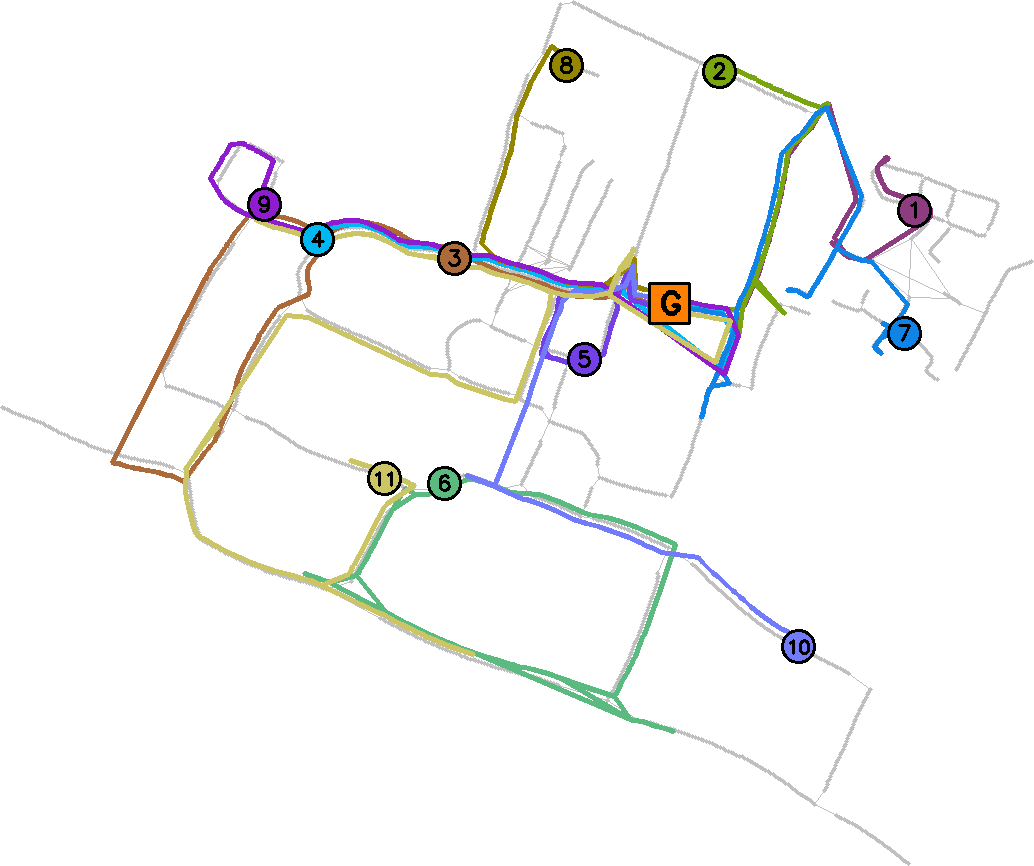 We present an approach for efficiently learning goal-directed navigation policies on a mobile robot, from only a single coverage traversal of recorded data. The navigation agent learns an effective policy over a diverse action space in a large heterogeneous environment consisting of more than 2km of travel, through buildings and outdoor regions that collectively exhibit large variations in visual appearance, self-similarity, and connectivity. We compare pretrained visual encoders that enable precomputation of visual embeddings to achieve a throughput of tens of thousands of transitions per second at training time on a commodity desktop computer, allowing agents to learn from millions of trajectories of experience in a matter of hours. We propose multiple forms of computationally efficient stochastic augmentation to enable the learned policy to generalise beyond these precomputed embeddings, and demonstrate successful deployment of the learned policy on the real robot without fine tuning, despite environmental appearance differences at test time.
[arXiv]
[website]
We present an approach for efficiently learning goal-directed navigation policies on a mobile robot, from only a single coverage traversal of recorded data. The navigation agent learns an effective policy over a diverse action space in a large heterogeneous environment consisting of more than 2km of travel, through buildings and outdoor regions that collectively exhibit large variations in visual appearance, self-similarity, and connectivity. We compare pretrained visual encoders that enable precomputation of visual embeddings to achieve a throughput of tens of thousands of transitions per second at training time on a commodity desktop computer, allowing agents to learn from millions of trajectories of experience in a matter of hours. We propose multiple forms of computationally efficient stochastic augmentation to enable the learned policy to generalise beyond these precomputed embeddings, and demonstrate successful deployment of the learned policy on the real robot without fine tuning, despite environmental appearance differences at test time.
[arXiv]
[website]
-
One-Shot Reinforcement Learning for Robot Navigation with Interactive Replay In Proc. of NIPS Workshop on Acting and Interacting in the Real World: Challenges in Robot Learning, 2017.
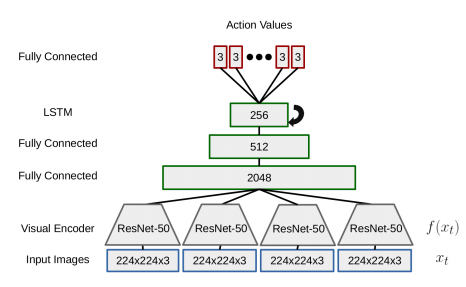 Recently, model-free reinforcement learning algorithms have been shown to solve challenging problems by learning from extensive interaction with the environment. A significant issue with transferring this success to the robotics domain is that interaction with the real world is costly, but training on limited experience is prone to overfitting. We present a method for learning to navigate, to a fixed goal and in a known environment, on a mobile robot. The robot leverages an interactive world model built from a single traversal of the environment, a pre-trained visual feature encoder, and stochastic environmental augmentation, to demonstrate successful zero-shot transfer under real-world environmental variations without fine-tuning.
Recently, model-free reinforcement learning algorithms have been shown to solve challenging problems by learning from extensive interaction with the environment. A significant issue with transferring this success to the robotics domain is that interaction with the real world is costly, but training on limited experience is prone to overfitting. We present a method for learning to navigate, to a fixed goal and in a known environment, on a mobile robot. The robot leverages an interactive world model built from a single traversal of the environment, a pre-trained visual feature encoder, and stochastic environmental augmentation, to demonstrate successful zero-shot transfer under real-world environmental variations without fine-tuning.
-
Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments In Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
 To enable and encourage the application of vision and
language methods to the problem of interpreting visually grounded
navigation instructions, we present the Matterport3D
Simulator – a large-scale reinforcement learning
environment based on real imagery. Using this simulator,
which can in future support a range of embodied vision
and language tasks, we provide the first benchmark dataset
for visually-grounded natural language navigation in real
buildings – the Room-to-Room (R2R) dataset.
To enable and encourage the application of vision and
language methods to the problem of interpreting visually grounded
navigation instructions, we present the Matterport3D
Simulator – a large-scale reinforcement learning
environment based on real imagery. Using this simulator,
which can in future support a range of embodied vision
and language tasks, we provide the first benchmark dataset
for visually-grounded natural language navigation in real
buildings – the Room-to-Room (R2R) dataset.
-
Multimodal Deep Autoencoders for Control of a Mobile Robot In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2015.
 Robot navigation systems are typically engineered
to suit certain platforms, sensing suites
and environment types. In order to deploy a
robot in an environment where its existing navigation
system is insufficient, the system must
be modified manually, often at significant cost.
In this paper we address this problem, proposing
a system based on multimodal deep autoencoders
that enables a robot to learn how
to navigate by observing a dataset of sensor input
and motor commands collected while being
teleoperated by a human. Low-level features
and cross modal correlations are learned and
used in initialising two different architectures
with three operating modes. During operation,
these systems exploit the learned correlations
in generating suitable control signals based only
on the sensor information.
Robot navigation systems are typically engineered
to suit certain platforms, sensing suites
and environment types. In order to deploy a
robot in an environment where its existing navigation
system is insufficient, the system must
be modified manually, often at significant cost.
In this paper we address this problem, proposing
a system based on multimodal deep autoencoders
that enables a robot to learn how
to navigate by observing a dataset of sensor input
and motor commands collected while being
teleoperated by a human. Low-level features
and cross modal correlations are learned and
used in initialising two different architectures
with three operating modes. During operation,
these systems exploit the learned correlations
in generating suitable control signals based only
on the sensor information.